Local AI Playbook.
Ollama, Hermes, autonomous agent companies. Cut cloud bills, own your stack, run private models at 30+ tokens per second on the GPU you already own.
5 titles · 25 free guides
What It Costs to Run an Autonomous AI Company
How much does it cost to run AI agents? A six-agent autonomous company runs on $28.50 a month. Here is the per-agent model breakdown and where the margin is.
from: Zero-Human Companies
Write a Hermes SKILL.md the Agent Actually Uses
How to write a Hermes skill: the SKILL.md format, the three ways skills reach the agent, and a copy-paste template the matcher actually loads with hermes -s.
from: Zero-Human Companies
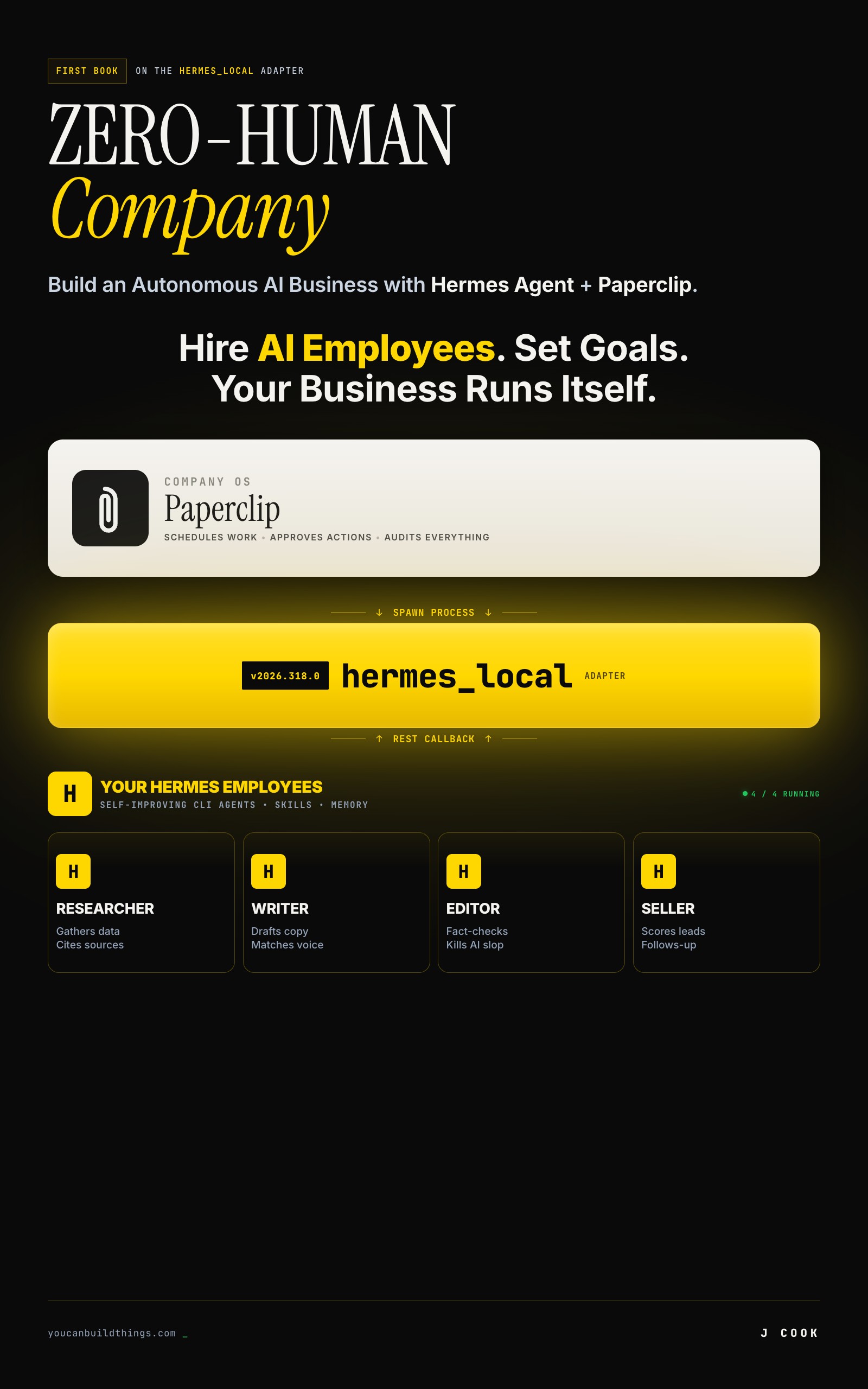
Where Hermes + Paperclip Agents Break (and the Fixes)
The real AI agent failure modes when you run Hermes + Paperclip: three cited GitHub bugs, the security traps, and the runaway-cost fixes that actually hold.
from: Zero-Human Companies
Install Paperclip AI and Launch Your First AI Company
How to install Paperclip AI: run one npx command, pass the doctor check, open the dashboard at localhost:3100, and create your first AI company and issue.
from: Zero-Human Companies
Wire Hermes Into Paperclip with the hermes_local Adapter
The hermes_local adapter runs Hermes Agent as a Paperclip worker. Configure one agent, assign an issue, fire a heartbeat, and watch a $0.02 run end to end.
from: Zero-Human Companies
Local vs Cloud AI Coding: When Local Loses
Are local coding models good enough? For most of your day, yes. The honest map of where local wins, where it loses, and how to decide before you fire a task.
from: Run Claude Code Locally
How to Pick a Local Model for Coding
The best local LLM for coding isn't the leaderboard winner. Pick by tool-call reliability and speed, with a model table and a benchmark you run yourself.
from: Run Claude Code Locally
Run a Local AI Coding Agent Free in 15 Minutes
Build a local AI coding agent on Ollama that edits real code offline. Install, pull qwen2.5-coder, run Codex, ship your first edit with the Wi-Fi off.
from: Run Claude Code Locally
Run Claude Code Locally with Ollama
Point the real Claude Code CLI at a local Ollama model through a LiteLLM proxy. The exact env vars, the config.yaml, and the version you must never install.
from: Run Claude Code Locally
Why Your Local AI Coding Agent Is Slow
Why is Ollama slow for coding? Almost never your hardware. Fix the 52-second tool call with three knobs: model size, quantization, and context length.
from: Run Claude Code Locally
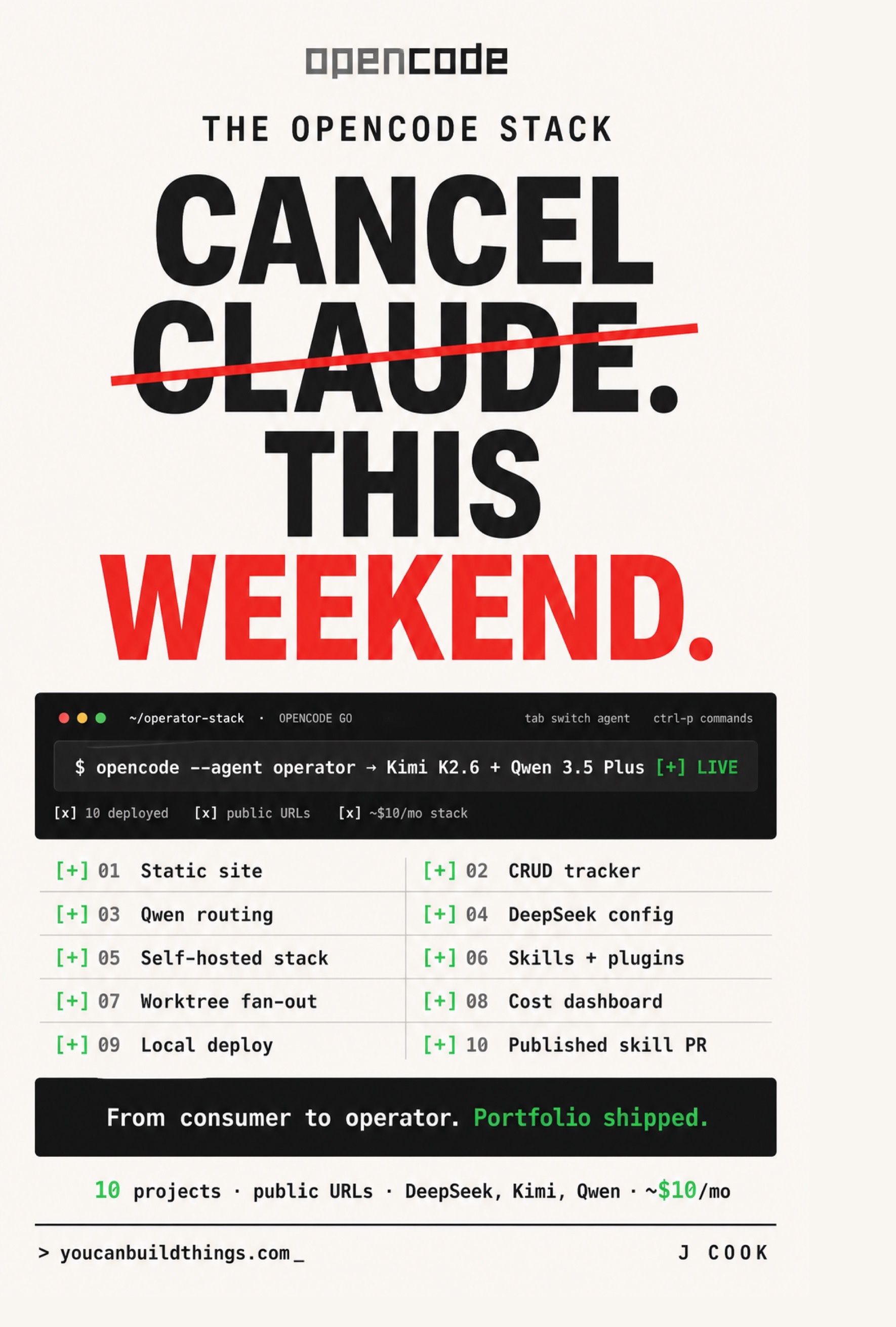
Install OpenCode and Ship in 10 Minutes
How to install OpenCode the right way, connect a provider, and ship a deployed public URL in ten minutes. Six steps, the three install gotchas, real token cost.
from: The opencode Stack
OpenCode Not Working? The 5 Failure Modes
OpenCode not working? The 5 documented failure modes with detection, cause, one-line fix, and prevention. Plus the weekly health-check script that catches them.
from: The opencode Stack
OpenCode Orchestrator + Fixer Routing, Wired
The opencode orchestrator fixer pattern: two models, two slots, one opencode.json. Three task-class routing recipes and an A/B receipt that cuts the bill 10x.
from: The opencode Stack
Self-Host OpenCode With Zero Outbound Tokens
How to self-host OpenCode with a local model and prove zero outbound API tokens with tcpdump. Hardware tiers, the provider config, and the silence receipt.
from: The opencode Stack
Keep OpenCode Under $1 a Day: Cost Dashboard
Build OpenCode token cost tracking that alerts at the $1/day line. The SQLite schema, the parser, the run-rate readout, and the four levers that cut spend.
from: The opencode Stack
How to Fit a 26B LLM on a 16GB GPU
Q4_K_M is not the floor. Importance-matrix quantization, IQ3_M, and per-tensor tricks let you run models that 'cannot fit' your GPU with usable quality.
from: Master Ollama - The Speed Playbook
How Much VRAM Do You Need for a Local LLM?
The exact formula for predicting VRAM use of any local LLM, plus the KV cache table you need before you waste 20 minutes downloading a model that crashes.
from: Master Ollama - The Speed Playbook
Ollama Modelfile: 3 Templates That Beat the Defaults
Default Ollama settings produce mediocre output. These 3 ready-to-copy Modelfiles for chat, code, and analysis fix it in 2 minutes with explicit reasoning.
from: Master Ollama - The Speed Playbook
Ollama vs llama.cpp: A Head-to-Head Speed Test
All three engines use llama.cpp. Here is the head-to-head test that debunks the 'double your speed' Reddit claim and tells you which one to actually run.
from: Master Ollama - The Speed Playbook
Why Is Ollama So Slow? A 6-Step Diagnostic
Your Ollama is stuck at 3 tok/s? The priority-ordered diagnostic that finds the bottleneck in 5 minutes, with the specific fix and a tok/s test for each.
from: Master Ollama - The Speed Playbook
How to Replace GitHub Copilot with Ollama in VS Code
Set up a free AI coding assistant in VS Code using Ollama and Cline. Seven real workflows tested with honest quality scores compared to GitHub Copilot.
from: Ship Local AI with Ollama
How to Route Queries to Multiple Ollama Models
Build a Python router that sends coding questions to CodeLlama and general queries to Llama 3. Keyword-based and AI-powered routing strategies compared.
from: Ship Local AI with Ollama
How to Secure Your Ollama Installation
Run this 30-second audit script to catch the exact misconfiguration that exposed thousands of Ollama instances to the public internet. Copy-paste fixes included.
from: Ship Local AI with Ollama
Ollama vs ChatGPT: Honest Benchmarks from 100 Prompts
Benchmark scores comparing local Ollama models against GPT-4o across coding, writing, reasoning, and more. Data from 100 test prompts on a consumer laptop.
from: Ship Local AI with Ollama