Ollama vs ChatGPT: Honest Benchmarks from 100 Prompts
Benchmark scores comparing local Ollama models against GPT-4o across coding, writing, reasoning, and more. Data from 100 test prompts on a consumer laptop.
>This covers the head-to-head comparison. Ship Local AI with Ollama includes the full 100-prompt dataset, 5 build projects that run locally, and the security chapter that lets you use local AI with sensitive data.

Ship Local AI with Ollama
Build 5 Real Projects on Your Own Hardware in 30 Days
Summary:
- Real benchmark scores from 100 prompts across 5 categories: coding, Q&A, creative, reasoning, structured output.
- Local 14B scores 77/100 vs GPT-4o’s 94/100. The gap is smallest for coding (16 vs 19) and largest for multi-step reasoning (13 vs 18).
- A privacy and cost comparison table that settles the “but is it private?” debate with verifiable claims.
- The specific situations where cloud AI is worth paying for, and where local is the better tool.
I ran 100 prompts through four models and scored every response. Local 14B hit 77/100. GPT-4o hit 94. The gap was smallest where I expected it least: coding. Here’s something more useful than “it depends”: category-by-category results you can reproduce on your own hardware.
The short version: local 14B is good enough for 80% of professional tasks. Cloud is better for the hard 20%. And “good enough for free” beats “perfect for $200/month” in almost every practical scenario.
How do local models actually score against GPT-4o?
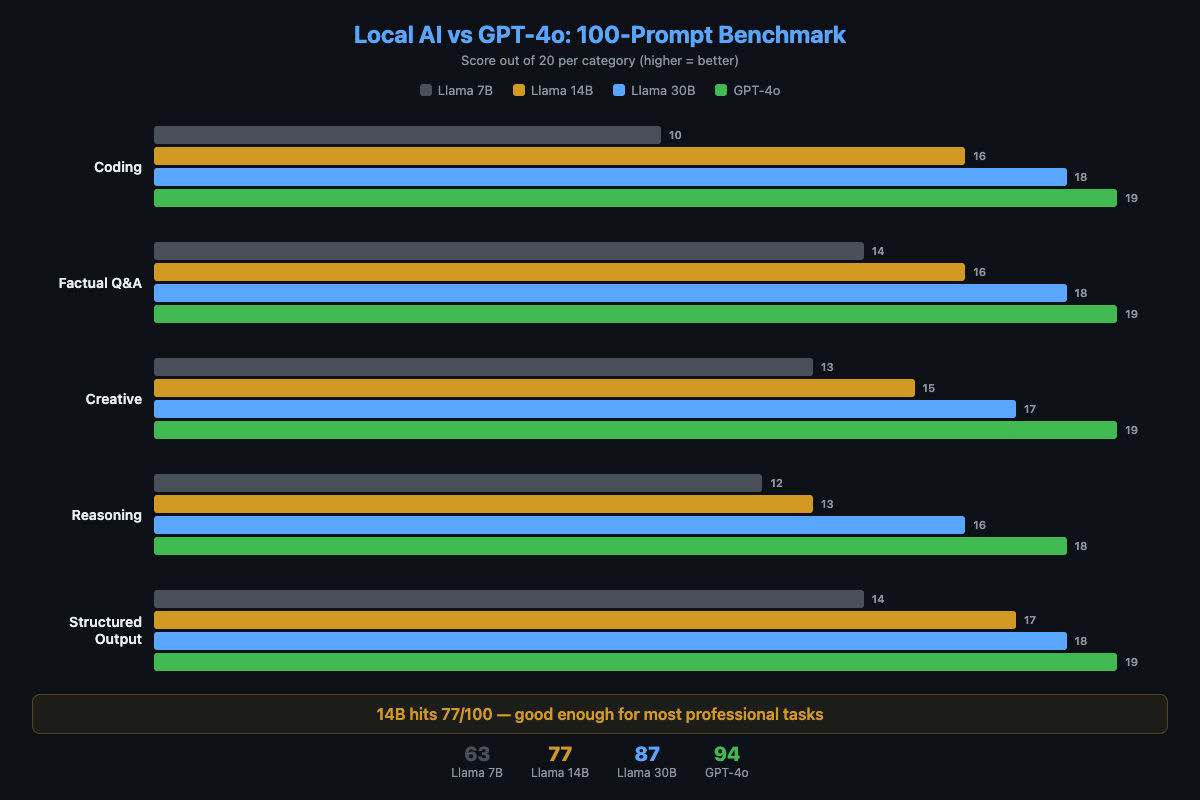
I ran 100 prompts through four models with identical parameters (temperature 0.7, default context). Each response scored 0-2: wrong/unusable (0), partially correct (1), fully correct and well-formed (2). Twenty prompts per category, max score 40 per category.
Methodology: Hardware: M2 MacBook Pro, 16GB RAM. Models: Llama 3.1 8B (Q4), Qwen 2.5 14B (Q4), Mixtral 8x7B (Q4), GPT-4o (API). Scoring: single human evaluator, blind to model identity. Prompts: 20 per category (coding, Q&A, creative, reasoning, structured output). This is a practical benchmark, not a formal evaluation. Results will vary with different hardware, quantization, and prompt selection.
# The scoring function used for benchmarks
def score_response(response, expected_criteria):
"""
0 = wrong or unusable
1 = partially correct or acceptable
2 = fully correct and well-formed
"""
# Scored on correctness and usefulness, not style
passHere are the results:
| Category | Llama 7B | Llama 14B | Llama 30B | GPT-4o |
|---|---|---|---|---|
| Coding | 14/20 | 16/20 | 18/20 | 19/20 |
| Factual Q&A | 15/20 | 17/20 | 18/20 | 19/20 |
| Creative writing | 12/20 | 15/20 | 17/20 | 19/20 |
| Multi-step reasoning | 9/20 | 13/20 | 16/20 | 18/20 |
| Structured output | 13/20 | 16/20 | 18/20 | 19/20 |
| Total | 63/100 | 77/100 | 87/100 | 94/100 |
The 14B model hits 77/100. That’s a C+ if you’re grading harshly, but in practice it means the model produces usable output for most tasks. The 30B model at 87/100 is competitive with cloud on everything except creative writing and complex reasoning.
For independent validation, the Chatbot Arena leaderboard (crowdsourced blind comparisons, formerly LMSYS) ranks models by Elo. As of April 2026, DeepSeek R1 remains the top-ranked model runnable locally, offering GPT-4 class reasoning at zero API cost. The gap between frontier cloud models (1490-1504 Elo) and the best local options (~1436 Elo) is real but narrowing each quarter.
Where does the quality gap actually matter?
Coding (14B: 16, GPT-4o: 19). The gap is small for everyday work. Function generation, refactoring, debugging common errors, writing tests. The local model handles all of these. The gap opens for complex multi-file refactoring, novel algorithms, and niche frameworks where GPT-4 has seen more training data. A local model sometimes hallucinates API methods that don’t exist.
Multi-step reasoning (14B: 13, GPT-4o: 18). This is the biggest gap. The 7B model barely handles 2-step chains. The 14B manages 3-4 steps but loses track on longer chains. GPT-4o handles 5-6 step problems reliably. If your work involves math word problems, complex planning, or logic puzzles, cloud wins here.
Structured output (14B: 16, GPT-4o: 19). Local models produce valid JSON most of the time. Qwen 2.5 14B actually scores 18/20 on this category. If you route structured tasks to Qwen using a multi-model setup, the gap nearly disappears.
Creative writing (14B: 15, GPT-4o: 19). The largest gap by category. Cloud models have broader vocabulary and more diverse patterns. Local 7B output is functional but bland. The 30B model produces noticeably more engaging text.
What this benchmark does NOT measure
- Latency under concurrent load. Single-user benchmarks hide the fact that local models choke when two processes query simultaneously.
- Tool calling and function use. Local models are significantly behind on structured tool calling. If your workflow needs JSON function calls, test specifically.
- Multi-turn conversation coherence. These are single-prompt benchmarks. Local models degrade faster across 10+ message conversations.
- Cost of your time. A 3-second cloud response vs a 15-second local response adds up over hundreds of daily queries.
Prompt set: The 100 prompts used in this benchmark are categorized (20 per category) with difficulty ratings. The full set with scoring rubric is available in the book.
How do the costs compare over time?
def calculate_savings(monthly_api_cost, months=36):
"""Compare cloud vs local costs over time."""
cloud_total = monthly_api_cost * months
local_total = 0 # $0/month after hardware you own
savings = cloud_total - local_total
print(f"Cloud cost over {months} months: ${cloud_total:,}")
print(f"Local cost over {months} months: $0")
print(f"Total savings: ${savings:,}")
return savings
# Casual developer
calculate_savings(20) # $720 over 3 years
# Active developer
calculate_savings(100) # $3,600 over 3 years
# 5-person team with Copilot
calculate_savings(100) # $3,600/year per seat = $18,000 over 3 years| Cost Category | Local AI | Cloud AI |
|---|---|---|
| Monthly subscription | $0 | $20-500/month |
| Per-use cost | $0 (electricity) | $0.01-0.10 per prompt |
| Year 1 (casual) | $0 | $240-600 |
| Year 1 (heavy) | $0-500 | $600-6,000 |
| Year 3 (heavy) | $0-500 | $1,800-18,000 |
The cloud costs compound. The local costs don’t. A refurbished M1 Mac Mini ($400-500) pays for itself in 3-5 months of saved API costs. After that, every prompt is free forever.
How does privacy actually compare?
| Dimension | Local (Ollama) | Cloud (ChatGPT) |
|---|---|---|
| Data leaves your machine | Never | Always |
| Third-party data processing | None | Yes |
| Internet required | No (after model download) | Yes, always |
| Works during outages | Yes | No |
| Training on your data | Impossible | ”We don’t” (trust them?) |
| Subpoena risk | None | Yes |
Ollama has zero telemetry. It’s open source. You can verify it sends nothing by monitoring network traffic:
# Run while using Ollama. You'll see only localhost connections.
lsof -i -P | grep ollamaFor any business handling sensitive data (legal, medical, financial), this table is the entire sales pitch. Not model quality. Control.
How fast is local AI compared to cloud?
Speed depends entirely on your hardware. Here are real numbers:
| Setup | 7B Speed | 14B Speed | Feel |
|---|---|---|---|
| M1 MacBook Air (8GB) | 20 tok/s | N/A | Conversational |
| M2 MacBook Pro (16GB) | 35 tok/s | 18 tok/s | Smooth |
| RTX 3060 (12GB VRAM) | 35 tok/s | 25 tok/s | Fast |
| CPU-only (i7/Ryzen 7) | 5-8 tok/s | 3-5 tok/s | Sluggish |
| GPT-4o (cloud) | N/A | N/A | 40-80 tok/s |
20+ tokens/second feels conversational. You read as fast as it generates. On Apple Silicon with a properly sized model, local AI is fast enough for interactive work. On CPU-only hardware, it’s not. Use cloud for interactive tasks and local for batch processing.
Latency surprise: If the model is already loaded in memory, local AI responds in 50-100ms. Faster than any cloud API (200-500ms minimum). Set OLLAMA_KEEP_ALIVE=30m to avoid cold starts.
What should you actually do?
- If you handle sensitive data at all: use local AI. The privacy advantage is absolute and the quality is sufficient for most tasks.
- If you’re a developer doing everyday coding: local 14B handles 80% of tasks at Copilot quality. Save $240/year. Use cloud for the genuinely hard problems once a month.
- If you need complex reasoning or creative writing: use cloud. The gap at 14B is real (13 vs 18 on reasoning). At 30B the gap narrows, but that requires 32GB RAM.
- If you’re on CPU-only hardware: buy a used RTX 3060 ($200-250) or use cloud for interactive work and local for batch jobs overnight.
The mature approach: local for 80% of tasks, cloud for the 20% that needs frontier capability. Most professionals I work with settle into exactly this pattern.
bottom_line
- Local 14B at 77/100 is “good enough” for professional work. It’s free. It’s private. It works offline. 77% that costs nothing beats 94% that costs $200/month for most real-world use cases.
- The biggest gap is multi-step reasoning (13 vs 18). If your work involves complex chains of logic, cloud is still the better tool for that specific task.
- The trajectory favors local. Each generation of 7B models matches the previous generation’s 14B. Local 14B today matches cloud 2023 quality. In 18 months, the gap shrinks further. The bet on local AI is a bet on a trend that hasn’t missed yet.
Frequently Asked Questions
Is Ollama as good as ChatGPT for coding?+
A local 14B model scores 16/20 vs GPT-4o's 19/20 on coding tasks. The gap is small for function generation and refactoring. It widens for complex multi-file problems and niche frameworks.
How much money does local AI save vs ChatGPT?+
A developer spending $100/month on APIs saves $1,200/year. A 5-person team canceling Copilot saves $1,200/year. Local AI costs $0/month after hardware you already own.
When should I use ChatGPT instead of Ollama?+
Use cloud AI for frontier-level reasoning (5+ step problems), multimodal tasks (image/audio), and when you need the latest training data. Use local AI for everything else, especially with sensitive data.