The OpenAI Codex 1M Context Window: 1M Is Really 258K
OpenAI Codex 1M context window. Layered: 1M API, 400K advertised, 258,400 reported, ~220K compaction breaks. The real ceiling and the issues that prove it.
>This explains the four layers. OpenAI Codex - The GPT-5.5 Playbook ships the recovery profile and the playbook that goes with it.

The Codex Migration Playbook
Switch from Claude to Codex. Build 12 Projects. Turn Your New Stack Into Paid Work.
Summary:
- The OpenAI Codex 1M context window number is real, but it lives in the API, not in your Codex subscription.
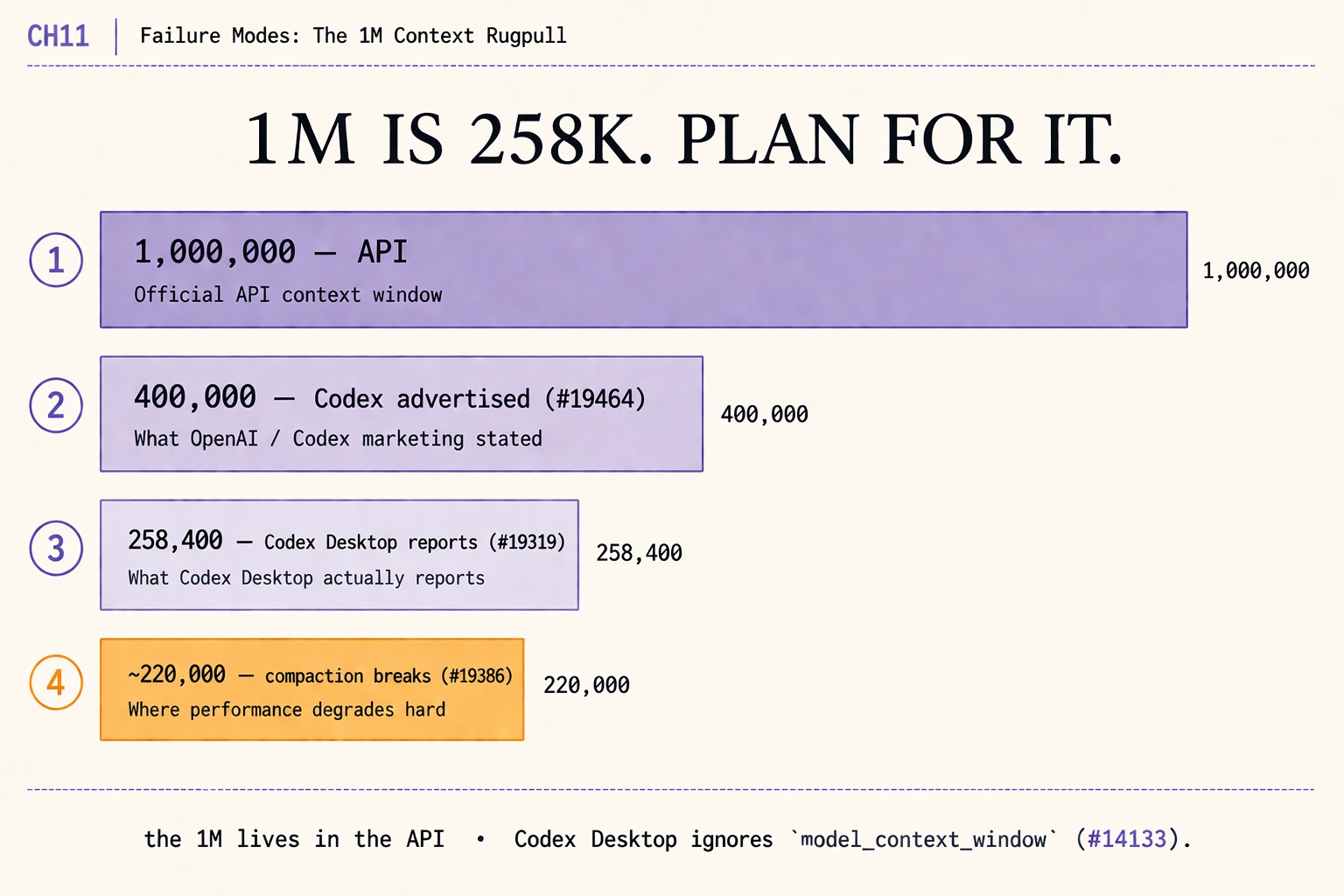
- Four layers stack down: 1,000,000 (API) → 400,000 (Codex advertised) → 258,400 (Codex Desktop reports) → ~220,000 (compaction breaks).
- The
model_context_windowsetting in~/.codex/config.tomlis silently ignored by Codex Desktop for GUI threads.- Plan briefs around 220K tokens, not 1M. The dashboard does not warn you; the JSONL on your disk does.
The OpenAI Codex 1M context window everyone is angry about is half right. The half it gets right: what you actually get on a Codex Desktop session is closer to 258,000 tokens, not the million OpenAI’s GPT-5.5 marketing page advertises. The half it gets wrong: there was never a 1M number for Codex specifically. The 1M lives in the API, where it always has. The frustration is real. The framing in most r/codex threads is not.
This is the same gap, taken apart in four layers. By the end you have the real number to plan around, the GitHub issues that prove each layer, and one config-line gotcha that costs an hour the first time it bites.
What is the actual OpenAI Codex 1M context window?
There is no single number. There are four. Every public complaint about the rugpull conflates them, and every config-file workaround the community proposes assumes one of the four when it should be assuming a different one.
Layer 1, the API: 1,000,000 tokens. GPT-5.5 supports a 1M-token context window when you call the OpenAI Responses API directly. This is the number on the GPT-5.5 marketing page. A developer who codes against the API gets it. It is real and it is reachable.
Layer 2, the Codex advertisement: 400,000 tokens. OpenAI’s own announcement caps GPT-5.5 in Codex at a 400K context window, per the user citing the announcement on issue openai/codex#19464. The number was never 1M for Codex. The community’s expectation that “Codex inherits GPT-5.5’s full 1M context” was the source of the rugpull frustration.
Layer 3, Codex Desktop in practice: 258,400 tokens. When you start a session in Codex Desktop, the live task_started event in your rollout JSONL reports the effective window. Two raw events from issue openai/codex#19319:
{"type":"task_started","model_context_window":258400}
{"type":"token_count","info":{"model_context_window":258400}}The same issue body shows the codex debug models output that explains why:
{
"slug": "gpt-5.5",
"context_window": 272000,
"max_context_window": 272000,
"effective_context_window_percent": 95
}272000 * 0.95 = 258400. Codex carves a 5% headroom out of the catalog window before any session starts. The user who measured this themselves and posted to r/codex is right; the number is real and reproducible. You can verify it in your own JSONL stream the next session you run.
Layer 4, compaction in practice: ~220,000 tokens. Per issue openai/codex#19386, compaction in Codex Desktop fails with “unrecoverable compaction failure” around 220K tokens despite the advertised 400K. The 258,400 from layer 3 is the headline. The 220K from layer 4 is the practical ceiling on a long session.
What broke when I tried to override it
The most subtle failure of the four. The model_context_window setting in ~/.codex/config.toml is silently ignored by Codex Desktop for GUI threads. Per issue openai/codex#14133, even setting model_context_window = 1050000 does not extend a GUI session past 258,400. Terminal codex exec sessions honor the override; Desktop GUI sessions do not. The user has no UI feedback that their setting was ignored.
A maintainer (@etraut-openai) confirms the cap on the duplicate issue #19409:
Codex supports a 400K-token context window for gpt-5.5. It does not support a 1M-token context window, at least not at this time. The default input context size for gpt-5.5 is 258400 which allows for a safe margin for compaction.
The user-side request, from @umikato on issue #19464 (165 reactions on the original post + 60 on the top reply):
Codex already has the idea of paying a higher consumption rate for a different capability tradeoff. I am not asking for free unlimited 1M context. I am asking for user choice. If 1M context is expensive, please keep 400K as the default. But allow advanced users to opt into larger context windows through
model_context_window, with a higher usage multiplier if needed.
The request is open at the time of writing. The cap is enforced at the Codex layer, not the API layer. You cannot opt out from config.toml today.
Where the four numbers come from
A clean reading of the four layers, with the issues that anchor each:
| Layer | Tokens | What it is | Issue |
|---|---|---|---|
| API | 1,000,000 | Official GPT-5.5 API context window | (marketing page) |
| Advertised | 400,000 | What OpenAI / Codex announcements stated | #19464 |
| Desktop reports | 258,400 | What task_started actually emits | #19319 |
| Compaction breaks | ~220,000 | Where performance degrades hard | #19386 |
The mismatch the community calls a rugpull is the gap between layers 1 and 3. The mismatch developers actually trip over in production is the gap between layers 3 and 4. Most r/codex complaint threads chase layer 1. The number that costs you a sprint is layer 4.
Why this matters for your config.toml
A config block the chapter 11 of the source book teaches verbatim, dropped here for the reader who needs the recovery profile today:
[profiles.background]
model = "gpt-5.5"
model_reasoning_effort = "medium"
sandbox_mode = "workspace-write"
approval_policy = "never"This is not a context-window override. It is the workaround for the fact that you do not get one. By running long sessions under a profile that auto-approves inside the workspace sandbox, you avoid the chat-loop reflex that fills context with re-asks and pushes the session toward the 220K compaction cliff. The smaller your accumulated context, the further you stay from the cliff.
The corollary: any cron pattern that runs Codex sessions overnight should chunk briefs to stay well under 200K tokens of accumulated context per session. A queue of small briefs that each finish and emit task_completed is a queue that does not hit compaction failures. A single 8-hour brief is one that does.
What should you actually do?
- If you read a r/codex thread that says “Codex has a 1M context window” → that number is API-only. For Codex CLI and Desktop sessions, the working ceiling is 258,400 reported and ~220,000 before compaction fails.
- If you set
model_context_window = 1050000in~/.codex/config.tomland your Desktop session still feels limited → it is. The setting is honored only by terminalcodex execsessions, not by Desktop GUI threads. Track the open issue at #14133 if you need that path opened. - If a cron pattern keeps hitting compaction failures → chunk the briefs. Aim for sessions that finish well under 200K tokens of accumulated context. Queue smaller briefs, not larger ones.
- If you want to verify the 258,400 number on your own machine → start a Codex CLI session, then
head -1 ~/.codex/sessions/*/*/*/rollout-*.jsonl | jqon the most recent file. The first event has the livemodel_context_windowfield. - If you want the 1M context window for real work → call the Responses API directly with your own integration code. Codex itself does not expose it.
bottom_line
- The 1M number is real and lives in the API. Codex sessions get 258,400 reported and ~220,000 usable before compaction fails. Plan around 220K, not 1M.
- The
model_context_windowconfig override does not work for Codex Desktop GUI threads. Issue #14133 is the receipt; it is open at the time of writing. - Most r/codex rugpull threads chase the wrong layer. The number that hurts your sprint is layer 4, not layer 1.
Frequently Asked Questions
Does OpenAI Codex actually have a 1M context window?+
No. The 1M number lives in the API. Codex Desktop reports 258,400 in its live `task_started` event. OpenAI's own announcement caps Codex at 400K. Compaction in Codex Desktop fails earlier than that, around 220K, per issue #19386.
Why does my `model_context_window` setting in config.toml not take effect?+
Codex Desktop ignores `model_context_window` for GUI threads, per issue #14133. Even setting `model_context_window = 1050000` does not extend a Desktop session past 258,400. The override is honored only for terminal `codex exec` sessions.
What context window should I actually plan briefs around?+
Plan around 200,000 to 220,000 usable tokens for Codex Desktop sessions. That is the practical ceiling before compaction fails. Anything above that risks losing session context mid-task. Queue smaller briefs for cron runs, not larger ones.