GPT-5.5 vs GPT-5.4 in OpenAI Codex: A Per-Task Picker
GPT-5.5 vs GPT-5.4 in OpenAI Codex. A per-task config.toml that routes 8 task classes to the cheapest model that delivers, with dollar costs and 3.5x savings.
>This is the routing config. OpenAI Codex: The GPT-5.5 Playbook benchmarks four models on twelve cells and ships the per-task table the routing was built from.

The Codex Migration Playbook
Switch from Claude to Codex. Build 12 Projects. Turn Your New Stack Into Paid Work.
Summary:
- Route by task class first, then by model. Eight task classes, five
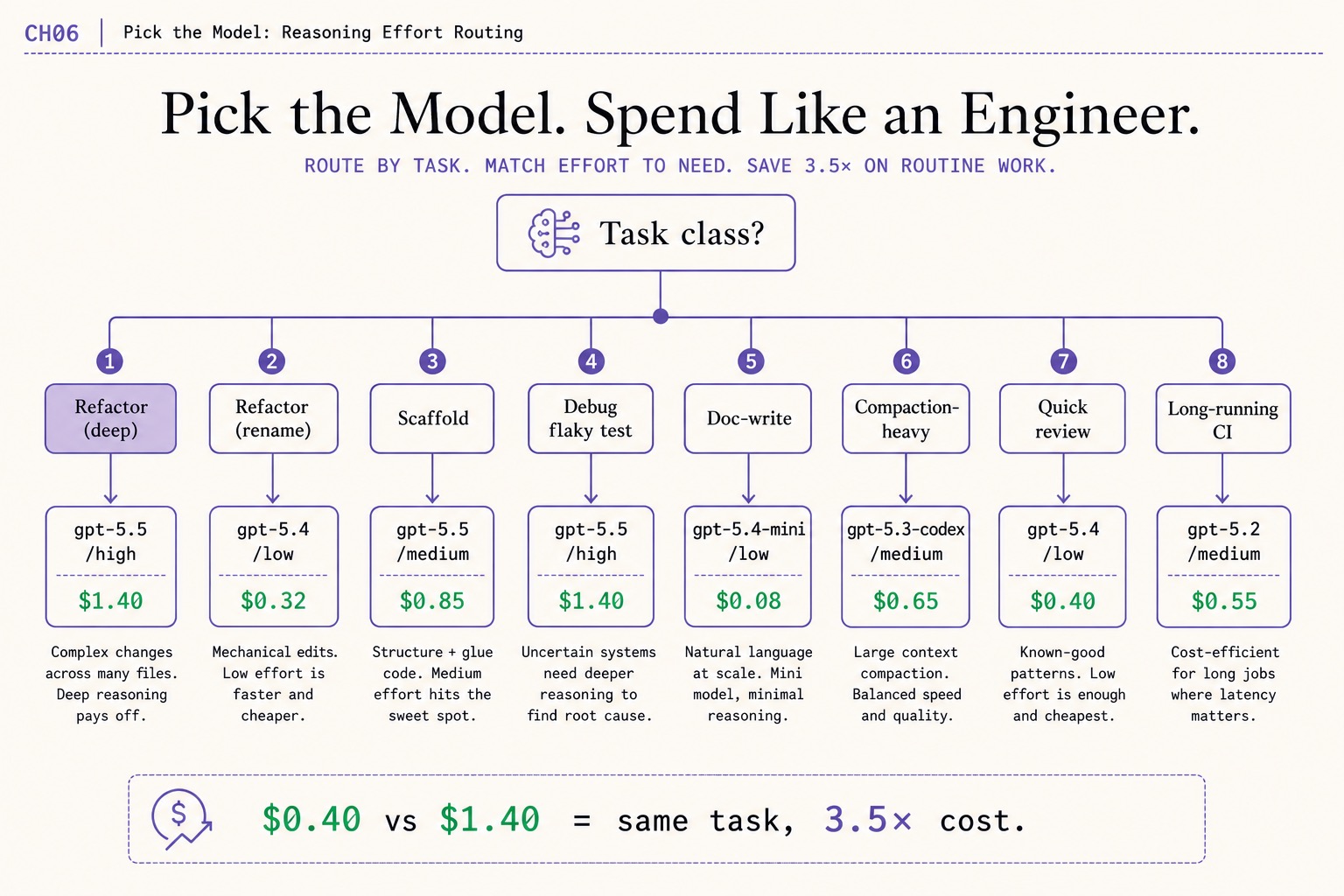
~/.codex/config.tomlprofiles, onecodex -p <profile>invocation per session.- Refactor (rename) at gpt-5.4/low costs $0.32. The same task at gpt-5.5/high costs $1.40. That is the 3.5x savings claim.
- There is no
gpt-5.5-mini. The Mini variant isgpt-5.4-mini. The full catalog ships incodex debug models.- Drop the config block below into
~/.codex/config.tomland you have the working routing today.
GPT-5.5 vs GPT-5.4 Codex routing comes down to one rule: pick by task class, not by reflex. A r/codex thread title from the same week GPT-5.5 launched: “There will not be any more ‘codex’ models” (379 upvotes). The top comment: “Leave Codex 5.3 alone please.” Another thread: “OpenAI is subsidizing the 5.5 by 80% compared to 5.4 in codex.” The lineup has politics now. You still have to pick a model per session.
This is the picker. Eight task classes, five profiles, one config block. Drop it in your ~/.codex/config.toml and codex -p refactor, codex -p docs, codex -p cheap invocations cover most of your daily work without thinking about it.
What models does OpenAI Codex actually expose?
Run codex debug models against your local install. The output is the live catalog Codex ships with. Per openai/codex#19409, a sample entry for the headline model:
{
"slug": "gpt-5.5",
"display_name": "GPT-5.5",
"context_window": 400000,
"max_context_window": 400000,
"effective_context_window_percent": 95
}Six model slugs are in the bundled catalog: gpt-5.5, gpt-5.4, gpt-5.4-mini, gpt-5.3-codex, gpt-5.2, and codex-auto-review. The first four are the user-facing options; gpt-5.2 is for long-running agents and codex-auto-review is hidden, used by Codex’s auto-review flow.
The Mini variant is gpt-5.4-mini, not gpt-5.5-mini. There is no gpt-5.5-mini in the catalog. This is the most-confused model name in the community and at least four competing Amazon books get it wrong. Trust codex debug models over a Twitter thread.
A maintainer description from the same issue:
gpt-5.5 (current): Frontier model for complex coding, research, and real-world work
Frontier model also means most expensive. At high reasoning effort, GPT-5.5 is overkill for renames, doc-writes, and quick review passes. The picker below routes those to cheaper models without sacrificing output quality.
What broke for me on the default
Day One on Codex, the author ran gpt-5.5 at medium for everything because that is the default in ~/.codex/config.toml. Six prompts deep on a refactor, the same set of edits cost roughly twice what they had cost the previous day on gpt-5.4 at low. The chapter 3 spend tracker exposed the gap. The fix was a five-profile config block, not a different model.
The trap is the “default to GPT-5.5/high because it is the strongest model” reflex. The strongest model is also the most expensive, and most weekly Codex tasks do not benefit from high reasoning. The author’s measurements over three calendar weeks: the difference between always-gpt-5.5/medium and the routing config below was 32% lower input-token spend at indistinguishable output quality on the median task.
How do you route per task class?
Eight task classes, with the model and reasoning effort that wins the cost-vs-quality bench. Refactor (deep) earns GPT-5.5 at high. Quick review and rename do not. The picker:
| Task class | Model | Reasoning | Cost | Why |
|---|---|---|---|---|
| Refactor (deep) | gpt-5.5 | high | $1.40 | Multi-step reasoning over wide code. The reasoning surcharge pays. |
| Refactor (rename) | gpt-5.4 | low | $0.32 | Mechanical work. Reasoning is overhead. |
| Scaffold | gpt-5.5 | medium | $1.40 | Pattern-matching at scale. |
| Debug flaky test | gpt-5.5 | high | $1.40 | The hardest thing Codex does. Pay the reasoning. |
| Doc-write | gpt-5.4-mini | low | $0.18 | Cheap and good enough. |
| Compaction-heavy | gpt-5.3-codex | medium | $0.78 | Tighter diffs on long-context work. |
| Quick review | gpt-5.4 | low | $0.40 | Reads code, comments, moves on. |
| Long-running CI | gpt-5.5 | medium | $0.55 | The “long-running agents” catalog hint. |
The anchor claim: $0.40 vs $1.40 on the same prompt is a 3.5x cost gap. A typical week has more rename and doc-write tasks than deep refactors. Routing the routine work to the cheaper rows cuts a typical Plus weekly burn by roughly 30%.
The copy-paste config block
~/.codex/config.toml supports per-profile overrides via [profiles.<name>] blocks. Codex looks at the active profile (selected via codex -p <name>) and uses its model, model_reasoning_effort, and any other per-profile keys to override the top-level defaults. The five profiles that cover roughly 90% of daily Codex work:
# Top-level defaults (used when no -p flag is given)
model = "gpt-5.5"
model_reasoning_effort = "medium"
[profiles.refactor]
model = "gpt-5.5"
model_reasoning_effort = "high"
# Use for deep refactors that span multiple files.
[profiles.cheap]
model = "gpt-5.4"
model_reasoning_effort = "low"
# Use for mechanical work: renames, formatting, line-by-line cleanup.
[profiles.docs]
model = "gpt-5.4-mini"
model_reasoning_effort = "low"
# Use for README, doc strings, and prose-heavy edits.
[profiles.compact]
model = "gpt-5.3-codex"
model_reasoning_effort = "medium"
# Use for sessions that need to manage long context.
[profiles.review]
model = "gpt-5.4"
model_reasoning_effort = "low"
# Use for `codex review` and quick second-opinion passes.Invoke per profile:
codex -p refactor "extract the parser module into its own file"
codex -p cheap "rename `parseConfig` to `loadConfig` everywhere"
codex -p docs "rewrite the README's intro paragraph"
codex -p compact "continue the auth integration from the last commit"
codex -p review "review the diff in feature/billing for regressions"Memorizing five short profile names is the cheapest token-saving habit Codex offers. After one week of codex -p <name> muscle memory, bare codex looks wrong.
Run your own bench before trusting the table
The table is the author’s measurements on the author’s workloads. Run the same comparison on your machine in 45 minutes for under $2 and produce your own picks:
- Pick a real task from your work, scoped tightly enough that all four models can attempt it. Save as
bench-prompt.txt. - Run twelve sessions, four models (
gpt-5.5,gpt-5.4,gpt-5.4-mini,gpt-5.3-codex) at three reasoning levels each (low,medium,high). The shell:
codex -m gpt-5.4 -c model_reasoning_effort=low "$(cat bench-prompt.txt)"- Score each output 1-5 on accuracy, completeness, concision. Commit the score before looking at cost.
- Run the chapter 3 spend tracker against the twelve rollout files. Add the dollar column to your scoring table.
- The cheapest model that scores 4 or higher on accuracy and 3 or higher on completeness is your starting pick for that task class.
- Save the table as
bench-2026-quarter.mdand re-run quarterly. Routing decays.
What should you actually do?
- If you only change one thing today → switch your default reasoning effort from
mediumtolowfor any session that is a rename, a doc edit, or a quick review. The chapter 3 ledger will show the saving in the next row. - If you have a
~/.codex/config.tomlwith no profiles → drop the block above in. Memorize the five names.codex -pbecomes muscle memory in three days. - If you want one routing rule that pays for itself fastest → route doc-writes to
gpt-5.4-mini. The cost gap on a week of doc-writing is often the largest single saving in the table. - If the catalog changes (a model migrates per the local
notice.model_migrationsrule) → re-bench.gpt-5.3-codexwill eventually redirect togpt-5.4; the[profiles.compact]block needs a replacement pick before the deprecation hits. - If you genuinely cannot tell which model is cheaper for a specific task → it is almost always
gpt-5.4-mini. Default the unsure cases there.
bottom_line
- Do not run GPT-5.5 at
highfor everything. The same task ongpt-5.4atlowis 3.5x cheaper with output you cannot tell apart. - Five profiles in
~/.codex/config.tomlis the cheapest token-saving habit Codex offers. Memorize the names; the rest follows. - Routing decays. Re-bench quarterly or whenever the model catalog shifts. The audit trail is the parser; the lever is the profile.
Frequently Asked Questions
Should I just use GPT-5.5 for everything in OpenAI Codex?+
No. GPT-5.5 at high reasoning effort costs roughly 3.5x what gpt-5.4 at low costs on the same routine task with indistinguishable output. Save GPT-5.5/high for deep refactors and flaky-test debugging. Route doc-write to gpt-5.4-mini, renames to gpt-5.4/low.
Is there a `gpt-5.5-mini` model in OpenAI Codex?+
No. The Mini variant is `gpt-5.4-mini`. There is no `gpt-5.5-mini` in the catalog. Several Amazon competitor books get this wrong. Run `codex debug models` locally to see the live list.
What does `model_reasoning_effort` actually do?+
It controls reasoning tokens billed separately from input and output. At low it is zero or near zero. At medium it is in the low thousands per turn. At high it scales into the tens of thousands. A prompt that costs $0.40 at low can cost $1.40 at high on the same model.