How to Build a Self-Improving Claude Code Skill
Build a self-improving Claude Code skill the honest way: a human-gated workflow where Claude proposes diffs you approve, plus the $40 runaway to avoid.
>This covers the workflow. Claude Code Skills: The SKILL.md Playbook goes deeper on memory skills, skill generators, and combining all three patterns.
Claude Code Skills
The SKILL.md Playbook — Wire Your AI to Build and Ship in One Weekend
Summary:
- A self-improving skill is a human-gated workflow, not a Claude Code feature that edits itself.
- The full base skill with Self-Evaluation Criteria, Update Conventions, and Manual Workflow Notes.
- The exact 6-step loop where every transition is driven by you.
- The $40 runaway mistake and the three guardrails that prevent it.
Type how to build a claude code self improving skill into any forum and you get the same wrong answer: “make a skill that rewrites itself.” That mechanism does not exist. Nothing in Claude Code automatically re-runs evaluation logic on your skill files. A self-improving skill is a workflow you drive on demand, where Claude proposes edits and you approve them. Build it that way and it’s powerful. Build it as an autonomous loop and it sets $40 on fire in 45 minutes.
What is a self-improving Claude Code skill, really?
A self-improving Claude Code skill is a normal skill plus three things: success criteria you prompt Claude to evaluate against, conventions for how proposed edits should look, and a human checkpoint that gates every file change. The first two live in the SKILL.md. The third lives in your hands.
Why it matters: a static skill rots. You write “the right way to do X,” the codebase moves, nobody updates the skill. The honest workflow keeps a skill current without ever letting it edit itself behind your back. Here’s the demand, from a developer on r/ClaudeAI (parent post 12 upvotes / 39 comments):
i developed something like that for my own wrapper i called it “living skill system” — Skills are organisms, not files… Static skill libraries rot — the team adds a “right way to do X”, then the codebase changes and nobody updates the skill. — u/No_Strain_2140, r/ClaudeAI
People want skills that stay current. The trap is believing Claude does the staying-current for you. It doesn’t. You do, with one prompt at a time.
The base skill
Start from a normal skill (a code-review skill works well) and add three sections. Save at .claude/skills/code-review/SKILL.md:
---
name: code-review
description: Use this skill when reviewing pull requests or diffs. Prioritizes bugs and security over style. One sentence per issue with a specific fix. Top-5 limit. Includes self-evaluation criteria the user can prompt against.
---
# Code Review
## Instructions
- Focus on bugs, security, performance (in that order)
- State each issue in one sentence with a specific code fix
- Limit to 5 highest-priority items
## Self-Evaluation Criteria
When the user explicitly asks you to evaluate this skill's output:
1. Did the review catch a real bug (not just style)?
2. Did each suggested fix make sense in context?
3. Were obvious issues missed that the developer flagged manually?
## Update Conventions
When the user explicitly asks you to propose edits:
- If a category of bug is consistently missed, add it to the priority checklist
- Maximum skill file size: 60 lines. If an addition would exceed it,
propose removing the least-useful existing rule first
- Output proposed edits as a unified diff for the user to review
## Manual Workflow Notes
- This skill does NOT modify itself. It only generates proposed edits when prompted.
- The user runs the workflow on demand, reads the proposal, applies it manually.The load-bearing section is “Manual Workflow Notes.” It states the discipline plainly: Claude proposes, the human disposes.
The 6-step loop (every transition is driven by you)
Here is the corrected loop. Notice each arrow is a thing you do, not something that happens on its own:
- You: “review this PR.” Claude reviews it.
- Claude returns the review.
- You: “evaluate that review against the Self-Evaluation Criteria in the skill.”
- Claude proposes a specific edit as a unified diff. This is the human gate.
- You read the diff.
- You accept and apply it (or ask Claude to apply the exact diff after you confirm).
The prompt for step 3 and 4, verbatim:
# After Claude finishes a review, in the same session:
"Evaluate your output against the Self-Evaluation Criteria in the
code-review skill. If gaps exist, propose specific edits to the
SKILL.md as a unified diff. Do not modify the file."Step 4 returns something you can actually read and reject, a unified diff like:
--- a/.claude/skills/code-review/SKILL.md
+++ b/.claude/skills/code-review/SKILL.md
@@ Instructions
- Focus on bugs, security, performance (in that order)
+- Check for race conditions in async handlers (missed on PR #214)A real month of this, from the chapter: day 1, Claude misses a race condition; you prompt the evaluation, it proposes adding “check for race conditions in async handlers,” you apply it (skill grows 20 → 23 lines). Day 4, it catches a race condition unprompted. Day 12, a type-coercion miss; one more line. Over a month the skill learned three patterns and grew six lines. Cost: small, because every iteration was a deliberate prompt and you stopped when you had what you needed.
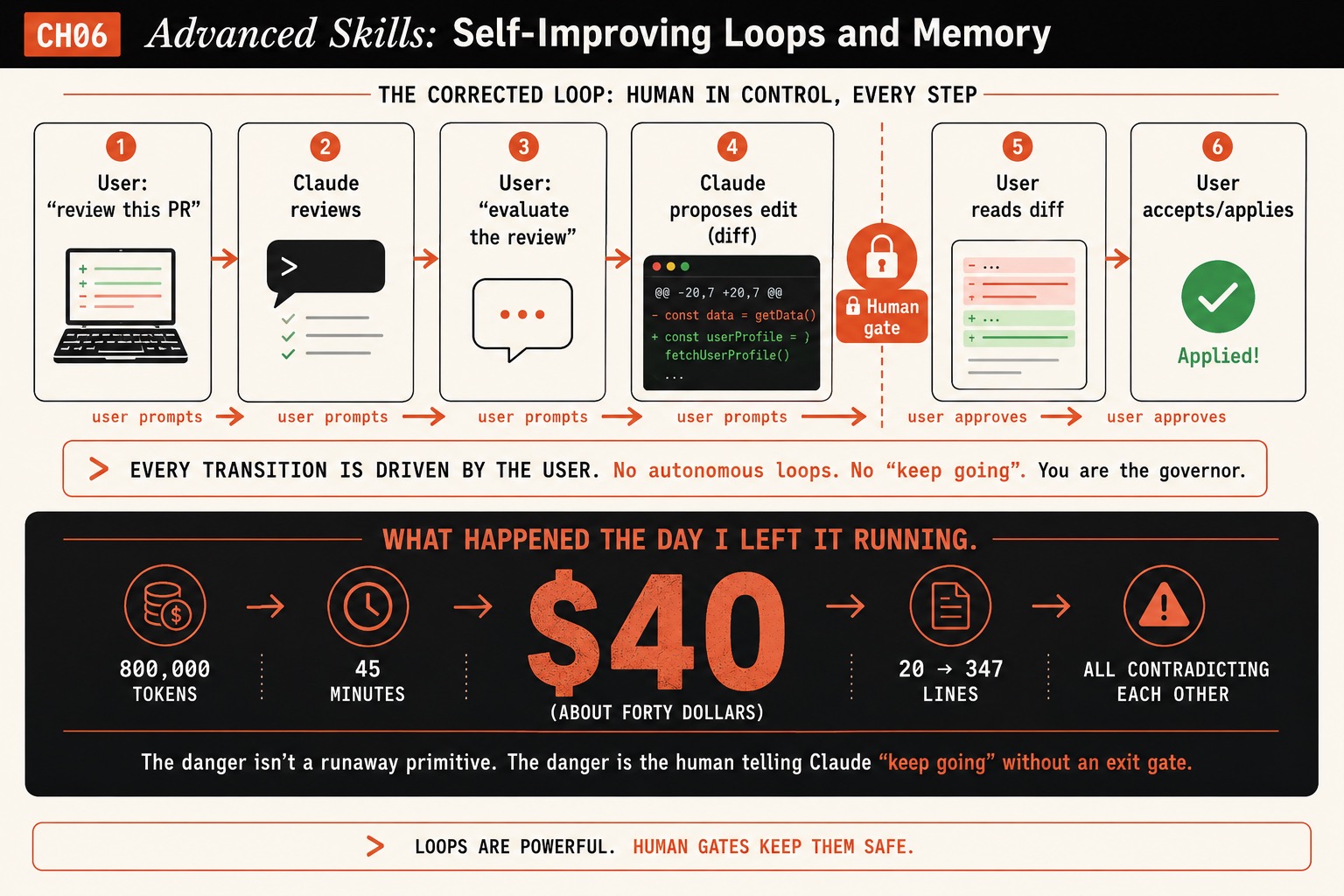
What broke: the $40 runaway
The first time this ran, it wasn’t human-gated. The prompt was “keep evaluating and proposing improvements until it’s converged,” and the session was left unattended. Claude evaluated, proposed, applied, re-evaluated the new output, proposed again, for 45 minutes. The skill file grew from 20 lines to 347, most of them contradicting each other. The session chewed through roughly 800,000 tokens. At then-current pricing, about $40.
The danger was never a runaway system primitive. There is no primitive. The danger was a human telling Claude “keep going” with no exit gate. That is the entire reason every transition in the loop above is a manual prompt.
What should you actually do?
- If you want a skill to stay current: add the three sections above and run the loop one round per session, only when you saw something worth refining.
- If your API bill spiked and a skill ballooned to 200+ lines: you skipped the human gate. Revert and re-cap:
git log --oneline .claude/skills/code-review/SKILL.md
git checkout <last-good-hash> -- .claude/skills/code-review/SKILL.md- If you want this across many skills: keep each skill in git, set an Anthropic budget alert at 120% of expected spend, and review weekly which skills grew more than 10 lines.
Three guardrails are non-negotiable: a human gate on every file change, a hard size cap with remove-before-add, and version control so any bad edit is one git checkout away.
bottom_line
- A self-improving skill is a workflow you drive, not a feature that edits itself. The “it updates itself automatically” promise is the exact thing that burns money.
- One deliberate round per session, with you reading every proposed diff, is bounded and cheap. “Keep iterating until convergence” is how you lose $40 in 45 minutes.
- The skill that says “this skill does NOT modify itself” in its own body is the one that stays useful a month later.
Frequently Asked Questions
Does a self-improving Claude Code skill update itself automatically?+
No. Nothing in Claude Code re-runs evaluation logic on its own. It is a workflow you drive: you prompt the evaluation, Claude proposes a diff, you approve and apply it.
How much does the self-improvement workflow cost?+
Run deliberately (one round per session), each round is roughly 1,000-2,000 tokens, a few cents. Left running unattended with 'keep iterating', one session burned about 800,000 tokens and $40.
Can a self-improvement workflow make a skill worse?+
Yes, with no size cap or too-loose criteria. The skill accumulates contradictory rules and output quality drops. Cap the file at 60 lines and require a removal before any addition.