What Is llms.txt? (And Does It Actually Help SEO)
What is llms.txt? A curated Markdown map at your site root that helps AI agents use your site. It does not get you cited. Here's how to build a real one.
>This builds the map. Get Cited by AI goes deeper on the two layers, validating with Lighthouse honestly, and where the agentic web (WebMCP) is actually heading.

Get Cited by AI: Show Me the Number
No-Hype Answer Engine Optimization for SaaS Founders and Site Owners
Summary:
- What llms.txt is: a curated Markdown map at your site root, for agents and models.
- Why it does not get you cited, and why that is fine once you separate the two layers.
- The spec, with a real file you can model on, not the empty stub everyone ships.
- How to validate it in Lighthouse honestly, and what passing actually proves.
What is llms.txt? It is a curated Markdown file you put at the root of your site, at /llms.txt, that hands AI models and agents a clean map of your most useful pages. That is the entire idea. The fight you have seen in the forums, where one person says Google calls it unnecessary and another points to Google’s own Chrome team praising it, dissolves the moment you see that those two camps are talking about two different jobs. Here is the honest version, and how to build a file that does the real one.
What is llms.txt?
It is a plain-Markdown index card for machines: here is what we are, here is where the important stuff lives. It was proposed by Jeremy Howard at Answer.AI, and its job is to let a model or agent use your site without wading through your navigation, popups, and footer. The spec is refreshingly small. The only required element is a single H1 with your site name. Everything else is optional but recommended, and the optional parts are what make it useful:
# Title
> Optional one-line summary of what you do
Optional free-text notes (e.g. "for write actions, use the API")
## Section name
- [Link title](https://example.com/page.md): what's on this page
## Optional
- [Link title](https://example.com/extra.md)The spec lives at llmstxt.org. Required: the H1. Recommended: a blockquote summary under it, then H2 sections that are each a Markdown list of links with a short note on each. The special ## Optional heading means exactly what it says: links an agent can skip when it needs to keep the context short.
Does llms.txt help SEO or get you cited?
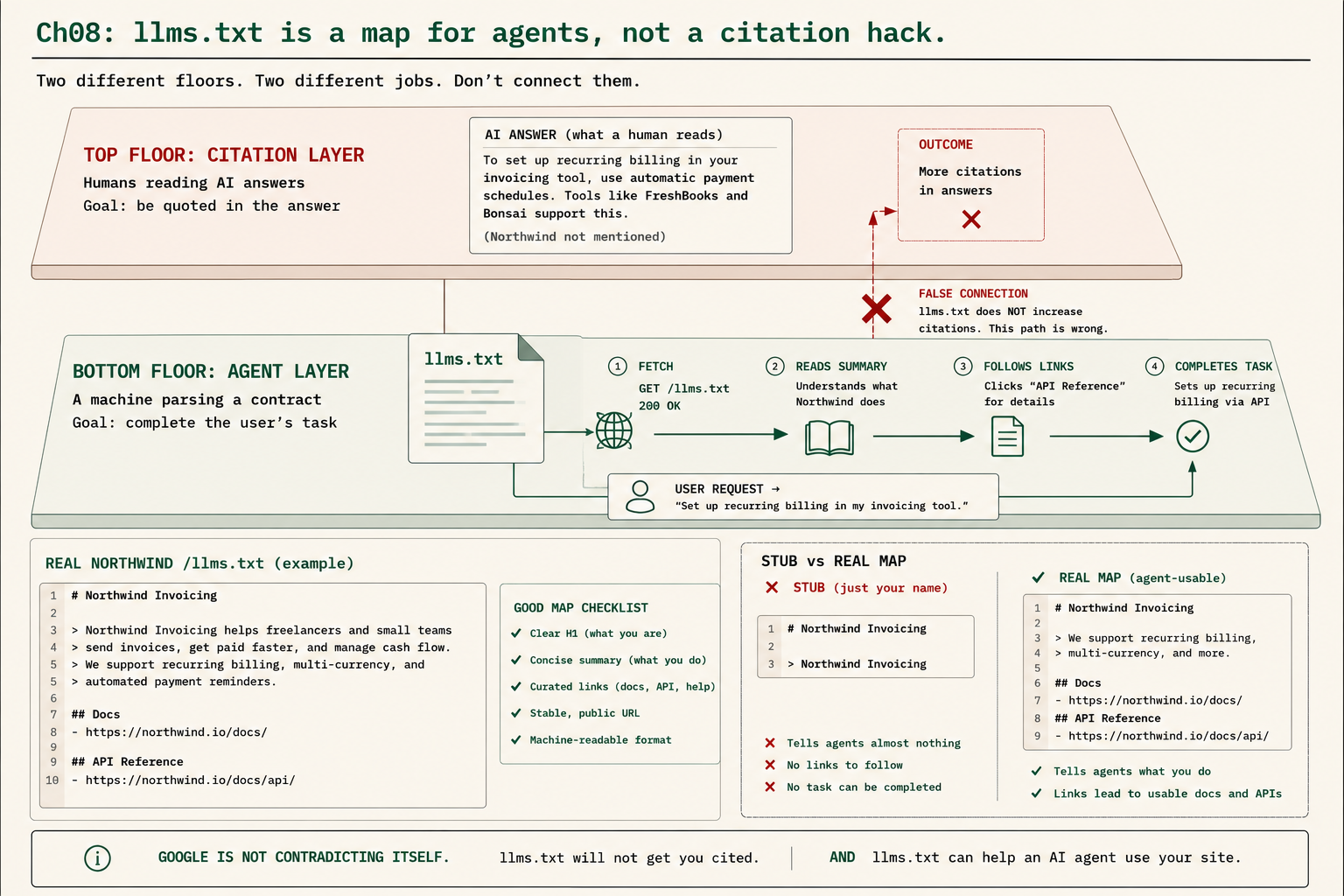
No, and anyone telling you otherwise is selling something. Google has said the idea that llms.txt boosts your visibility in AI answers is speculative, and you should believe Google over a vendor pitching a text file as a citation hack. This is where the two-layer split matters, because conflating the layers is the whole engine of the grift.
The citation layer is humans reading AI answers, where the goal is to be quoted. llms.txt does nothing here. Citations are earned by reachable, quotable, answer-first pages. The agent-readability layer is a machine parsing a contract so it can act on your site. That is where llms.txt lives. So Google is not contradicting itself when its search team says you do not need the file and its Chrome team says the file helps agents. Both statements are true: llms.txt will not get you cited, and llms.txt can help an AI agent use your site. The only people who are wrong are the ones collapsing those two claims into one muddled pitch.
How an agent actually uses your map
The agent layer feels abstract until you watch it work, so here is the kind of scenario becoming ordinary. A freelancer tells their AI assistant: “set up recurring billing on my Northwind account.” The assistant is an agent now, not a chatbot. It has to do something on a site, not describe one. With a real llms.txt, it runs four steps:
THE AGENT FLOW (what a good llms.txt enables)
1. FETCH gets /llms.txt
2. UNDERSTAND reads the summary, learns what you do and who you serve
3. FOLLOW follows the curated links into your real docs / API
4. COMPLETE creates the recurring invoice on the user's behalfWithout the file, the agent is reduced to scraping your rendered homepage, guessing your structure from menus, and often giving up, because most of the web is write-only to machines: readable by humans, opaque to agents. That is the entire value proposition, and notice it has nothing to do with citations. As agents get more common, being the site they can operate, instead of the one they bounce off, becomes a real edge.
Build a real one, not a stub
Here is the part almost everyone gets wrong: the file is the easy part, the contents are the point. Most llms.txt files in the wild are stubs, an H1 and a link or two that teach an agent nothing it could not get from your homepage. A real one is an actual curated map. Model yours on this:
# Northwind Invoicing
> Northwind helps freelancers and small agencies send invoices, accept card
> and ACH payments, and automatically chase overdue clients. Free plan
> available; paid tiers add recurring billing and team seats.
For account-specific or write actions, use the API (see API Reference), not this file.
## Docs
- [Quickstart](https://example.com/docs/quickstart.md): Send your first invoice in five minutes
- [Pricing & plans](https://example.com/pricing.md): Free, Pro, and Team tiers and limits
## API Reference
- [Invoices API](https://example.com/docs/api/invoices.md): Create, send, void, list invoices
- [Authentication](https://example.com/docs/api/auth.md): API keys, scopes, rate limits
## Optional
- [Changelog](https://example.com/changelog.md): Release notesRun your map through the good-map checklist before you ship it. Five things separate a real map from a stub:
- Clean and labeled one H1 that names the entity, no clutter.
- Curated, not everything the pages an agent actually needs, not a scripted dump of every URL.
- Links to your real docs the quickstart, the API reference, the pricing, in clean Markdown.
- Plain summaries, no hype “we are revolutionizing teamwork” tells an agent nothing; facts do.
- Stable, public location served at
/llms.txt, reachable without a login, as plain text.
There is an optional power-user tool that expands your file into one context blob you can hand to a model:
pip install llms-txt
llms_txt2ctx llms.txt > llms-ctx.txtTwo gotchas that will bite you. The package is llms-txt with a hyphen, but the command is llms_txt2ctx with underscores, so pip install llms_txt2ctx fails. And the command actually fetches every URL in your file to inline each page, so point it at real, reachable URLs, not placeholder links, or it throws a connection error the moment it hits a host that does not resolve.
What broke: the stub, the stale map, the dump
Most llms.txt files fail in a handful of predictable ways, and dodging them puts you ahead of nearly everyone who has shipped one. The stub: an H1 and one link, conveying nothing. If your file is shorter than your email signature, it is a stub. The stale map: you write a good file, redesign your docs, and never update it, so now it points agents at dead links, which is worse than no file. Put it on your sitemap’s maintenance schedule. The uncurated dump: a script lists every URL on the site with no notes and no hierarchy. That is a phone book, not a map, and it buries the useful pages in noise. Marketing fluff: a summary that reads like a slogan instead of stating what you do. Mis-serving it: behind auth, at the wrong path, or returning a server error, which is the one case the Lighthouse check will actually flag.
On Lighthouse: Google now checks for llms.txt, and the reliable way to run it is the command line, because the audit lives in a newer category that shipped in the npm tool first:
npx lighthouse@latest https://yoursite.com --only-categories=agentic-browsing --viewBe honest about what passing means. A site with no llms.txt does not fail this; it returns Not Applicable, because the file is optional. The audit flags a problem only if your file is present but the server errors when fetching it. And passing makes no claim about your rankings or citations. It confirms your file exists and loads cleanly. That is the whole promise, so do not let anyone tell you a green check is a citation win.
What should you actually do?
- If you have no llms.txt → you are not being penalized; the Lighthouse audit returns Not Applicable. Add one only because it is a cheap, no-regret courtesy to agents, not to chase citations.
- If you already shipped a stub → rebuild it as a real map: a factual summary plus curated links to your docs, API, and pricing. Run the good-map checklist.
- If a vendor sells “llms.txt for more citations” → decline. That is the mislabel. The file is agent-readability, not citation, and Google says so.
- Whatever you ship → confirm it loads in a plain browser tab at
/llms.txt, then put it on the same update schedule as your sitemap so it never goes stale.
The bottom line
- llms.txt is a curated Markdown map for agents, not a citation hack. Google saying “you do not need it for search” and “it helps agents” are both true, about two different layers.
- The file is trivial; the contents are the work. If an agent read only your llms.txt and would have a real map of your site instead of just your name, you built the real thing. Otherwise you shipped a stub.
- Validate it with the Lighthouse command line, but read the result honestly. No file is Not Applicable, not a failure, and a passing check proves your file loads, nothing about citations.
Frequently Asked Questions
What is llms.txt?+
llms.txt is a curated Markdown file at your site root, at /llms.txt, that gives AI models and agents a clean map of your most useful pages. The only required element is an H1 with your site name; a summary and curated link sections are what make it useful.
Does llms.txt help SEO or get you cited by AI?+
No. Google has said llms.txt does not affect your citations or rankings, and you should believe that over any vendor selling it as a citation hack. It belongs to the agent-readability layer: it helps an AI agent use your site, not get you quoted.
What should go in an llms.txt file?+
An H1 with your site name, a blockquote summary of what you do, and H2 sections listing your genuinely useful pages with a short note on each. If an agent read only your file, it should have a real map of your site, not just your name.