Are AI Visibility Tools Accurate? Trust, Verify, Ignore
Are AI visibility tools accurate? No engine ships a brand-mention API, so every tracker is guessing. A trust-verify-ignore rubric to grade any tool you buy.
>This grades the tools. Get Cited by AI goes deeper on the free first-party stack, the manual baseline that catches a lying dashboard, and the monthly loop.

Get Cited by AI: Show Me the Number
No-Hype Answer Engine Optimization for SaaS Founders and Site Owners
Summary:
- Why no AI visibility tool can give you an exact number: there is no brand-mention API to read.
- The three data sources behind every tracker, and which one to trust, verify, or ignore.
- A five-question rubric you run on any tool before you pay a cent.
- The cross-check that catches a lying dashboard: hold its number against one you collected by hand.
Are AI visibility tools accurate? Not in the way the dashboards imply. Here is the load-bearing fact the marketing buries: OpenAI, Google, Anthropic, and Perplexity do not publish an analytics API for brand mentions. There is no official feed anyone can query to ask “how often did ChatGPT name my brand last month.” So every tracker you have ever been pitched is not reading your real number from the source, because there is no source to read. They are all inferring. The skill is grading the guess.
Are AI visibility tools accurate?
They are directionally useful at best, and dangerous when you treat their number as a count. Because no engine exposes the data, a tool showing “you were mentioned 47 times in ChatGPT this month” did not get that 47 from ChatGPT. It got it by running a sample of prompts and extrapolating. The number is a model’s output wearing the costume of telemetry.
Someone in a community thread gave the practice its perfect name: directional surveillance. That is exactly what the good tools do, run a sample of real prompts against the real engines and record what comes back. The honest ones say so. The dishonest ones bury the caveat, because “directional estimate from a prompt sample” does not sell as well as “your AI visibility score is 73.”
Why every tracker disagrees with the next one
The same brand gets two different numbers from two tools in the same week because they ran different samples, on different engines, at different moments, and extrapolated differently. Neither is the truth, because the truth, an exact count, is something neither can access. They are two estimates of an unmeasurable quantity.
The good news is that the honest vendors will tell you this if you read their docs. Here is Semrush, describing where its AI visibility data actually comes from:
We source billions of real prompts from AI search clickstream data and Google’s keyword dataset for AI Overviews… To estimate topic volume, we combine third-party data on real AI interactions with Semrush’s machine learning models.
Read that twice. The data is sampled from a clickstream and modeled with machine learning. It is not pulled from an official LLM feed, because none exists. That candor is exactly what you want to see. A tool that admits it is sampling is a tool you can work with. The one to fear is the dashboard that retreats into “proprietary methodology” when you ask where the number came from.
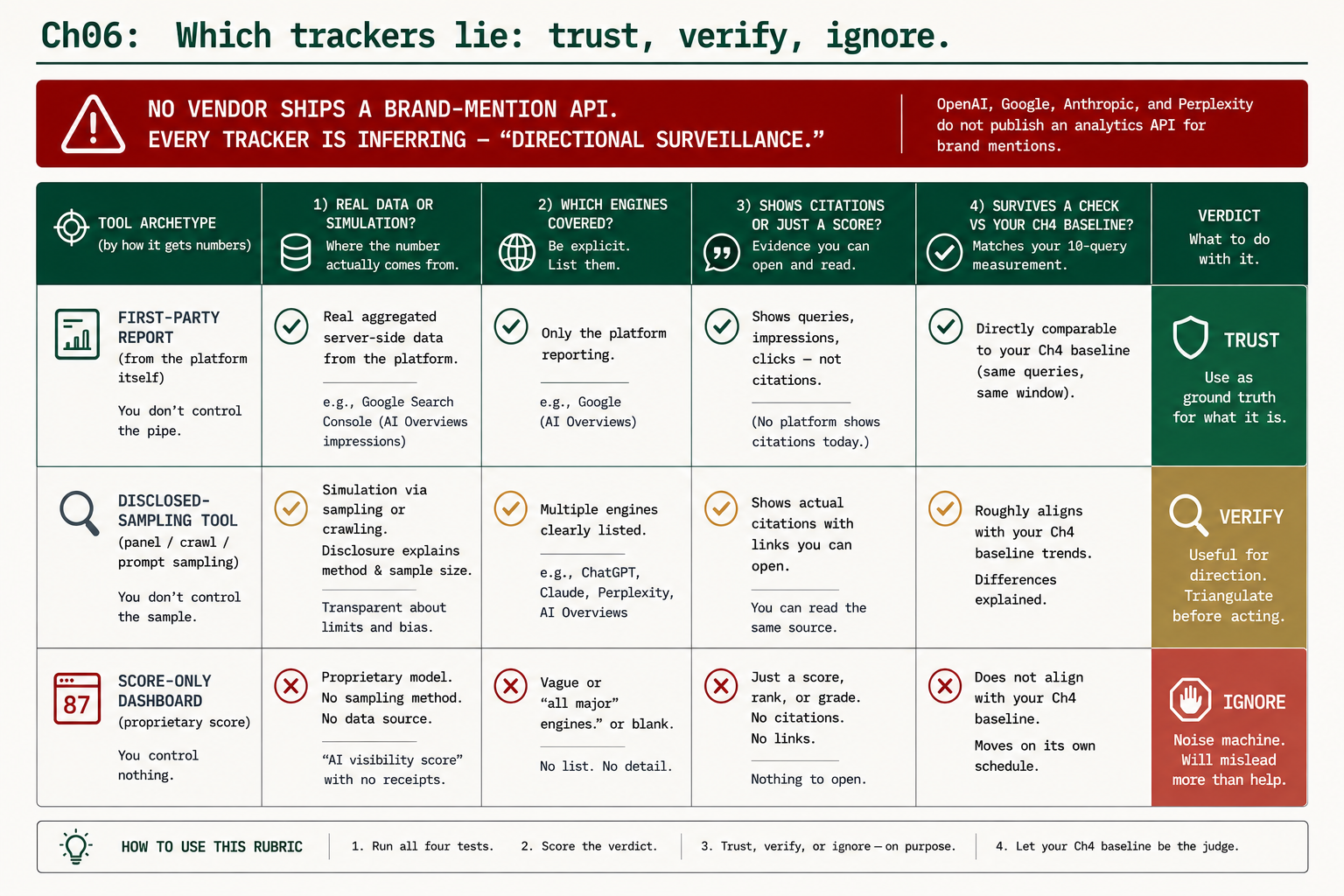
Three sources, three verdicts
Every AI-visibility number traces back to one of three sources, and identifying which one you are looking at is the whole skill. Sort any tool into trust, verify, or ignore:
| Source | What it is | Verdict |
|---|---|---|
| First-party platform report | Real telemetry from a platform about its own surface (Google Search Console AI report, Bing’s AI report, Microsoft Clarity) | Trust within its scope. It is reporting on itself, not guessing. Narrow but real. |
| Disclosed-sampling tool | Runs real prompts against real engines on a schedule and discloses the method (Otterly, Semrush’s visibility tooling) | Verify. Useful for direction and engine coverage you can’t check by hand. Triangulate against your own baseline before acting. |
| Score-only dashboard | A proprietary “AI Readiness Score” with no disclosed method, no engine list, no clickable citations | Ignore. A vanity meter you can grind without moving a single real citation. |
The first-party tier is trustworthy and narrow: Google’s report and Bing’s cover only their own engines, and neither shows you ChatGPT or Perplexity. The verify tier covers the engines the first-party dashboards cannot, which is its whole value, but you never take its number as gospel. The ignore tier shows you a grade and hides its work, which is the same chase-a-score trap dressed in an official-looking badge.
The five-question rubric
Stop evaluating tools by their marketing. Run this on the two or three you are considering, one row each:
THE TRUST RUBRIC — five questions, one verdict
1. Real data or simulation? Does it run real prompts (sampling),
or model a guess (simulation)?
2. Which engines covered? ChatGPT, Perplexity, Google AI, Claude,
Copilot, AI Overviews. Are YOUR buyers' in?
3. Citations or just a score? Does it show the actual answers and cited
domains, or only a grade?
4. Verifiable vs my baseline? Can you check its claims against a scorecard
you collected by hand?
5. Discloses its method? Will it tell you where the number comes from?
Vagueness is a verdict.
Mostly first-party / disclosed-sampling + clickable citations -> VERIFY
A score with no method, no engines, no citations -> IGNOREThe tell that separates verify from ignore is disclosure. A trustworthy tool answers “where does this number come from?” without flinching. Watch what an honest disclosure reads like next to a vague one:
HONEST (work with it):
"Data comes from a sample of real prompts run against ChatGPT,
Perplexity, and Google AI Overviews. Directional, not a hard count."
EVASIVE (close the tab):
"Our proprietary AI Readiness Index uses advanced signals to score
your visibility." (No engines. No sample. No citations. No number source.)Cross-check any tool against your own number
Here is the move that makes you bulletproof, and it only works because you can collect a baseline by hand. Hold the tool’s number up against the one you collected yourself.
A founder once reported his tracker showed he did not appear in ChatGPT at all, while in reality he got most of his traffic from ChatGPT. The tool was confidently, measurably wrong about him, because its prompt sample never included the queries his buyers actually used. He would never have known without his own ground truth. So before you trust any dashboard, do this:
THE CROSS-CHECK (10 minutes, beats any vendor's word)
1. Pick 3 of your real buyer-intent queries.
2. Run each by hand in ChatGPT, Perplexity, and Google AI Mode
(web search on). Note who got cited.
3. Compare to what the tool claims for those same queries.
Tool roughly matches your eyes -> lean on it for queries you can't check
Tool says invisible where you can
plainly see yourself cited -> its sample misses your queries; suspectYour hand-collected scorecard is the ground truth. The tool is a witness whose testimony you cross-examine, not a judge whose verdict you accept. Re-run the cross-check every quarter, because a tool that matched your reality in spring can drift out of agreement by fall as its sampling and the engines both change underneath it.
What should you actually do?
- If you only care about ~10 queries on 3 engines → skip the subscription. A free 20-minute hand audit already does the job, and you can reproduce every number.
- If you need scale (hundreds of queries across five engines) → pay for one disclosed-sampling tool, but only after it survives a spot-check against your hand baseline.
- If a tool shows a single “AI Visibility Score” and hides its method → ignore it, however slick the dashboard. A grade you cannot trace is the feeling of measurement, not the thing.
- Build the cheap stack first → Microsoft Clarity for real AI referral traffic, Google’s report for AI-features impressions, Bing’s for Copilot, all free and first-party, plus your hand-collected scorecard. Add at most one paid sampler on top, verified.
The bottom line
- No vendor ships a brand-mention API, so no tool can give you an exact count. Every number is an estimate, and a tool that admits it is more trustworthy than one that hides it.
- A “score” with no clickable citations and no disclosed method is a vanity meter. Trust first-party reports within their scope, verify disclosed-sampling tools against your own baseline, and ignore the rest.
- Your hand-collected number is the judge. A dashboard that cannot survive a spot-check against three queries you ran yourself does not earn its subscription.
Frequently Asked Questions
Are AI visibility tracking tools accurate?+
Not as exact counts. No AI engine publishes a brand-mention API, so every tracker samples prompts and models the rest, which is why two tools report different numbers for the same brand in the same week. Treat them as directional, not as truth.
Why do AI visibility tools show different numbers?+
Because each one runs a different sample of prompts against different engines at different moments, then extrapolates. There is no official feed to read, so the numbers are independent estimates of a quantity none of them can measure directly.
Should I pay for an AI visibility tool?+
Only if it covers engines you cannot easily check by hand and its numbers survive a spot-check against a baseline you collected yourself. If it just shows a score with no citations and no disclosed method, ignore it.