How to Pick a Local Model for Coding
The best local LLM for coding isn't the leaderboard winner. Pick by tool-call reliability and speed, with a model table and a benchmark you run yourself.
>This covers model choice. Run Claude Code Locally goes deeper on wiring the agent, tuning your hardware, and the troubleshooting runbook.

Run Claude Code Locally
Kill the $300 AI Bill with Free, Private Coding Agents on Ollama and Open Models
Summary:
- Why the leaderboard is the wrong test for an agent.
- A six-model comparison table for local coding, by the column that matters.
- The benchmark you run on your own machine to settle it.
- Name a primary and a fallback so you stop re-choosing every session.
The best local LLM for coding isn’t the one at the top of a leaderboard. It’s the one that survives an agent loop on your machine, and those are different models measured by different tests. Pick on the wrong test and you’ll pull a model that writes beautiful one-shot code and then falls apart the moment your agent asks it to chain a dozen tool calls.
Why is the leaderboard the wrong question?
The leaderboard is the wrong question because it measures one-shot code quality, and an agent never works one-shot. It runs a loop: call a tool, read the result, edit a file, run a test, read the failure, try again. A single task is a dozen of these round-trips.
For that to work, the model has to do something benchmarks barely test: format every tool call correctly, across a long chain, without dropping a step. That skill is tool-call reliability, and it’s nearly invisible on a code-quality score. So a model can ace “write me a function” and still be miserable in your agent, because on the third tool call it emits a chatty paragraph where the agent expected a structured call, and the whole task derails. The first is one shot. The second is the loop. The loop is your real life.
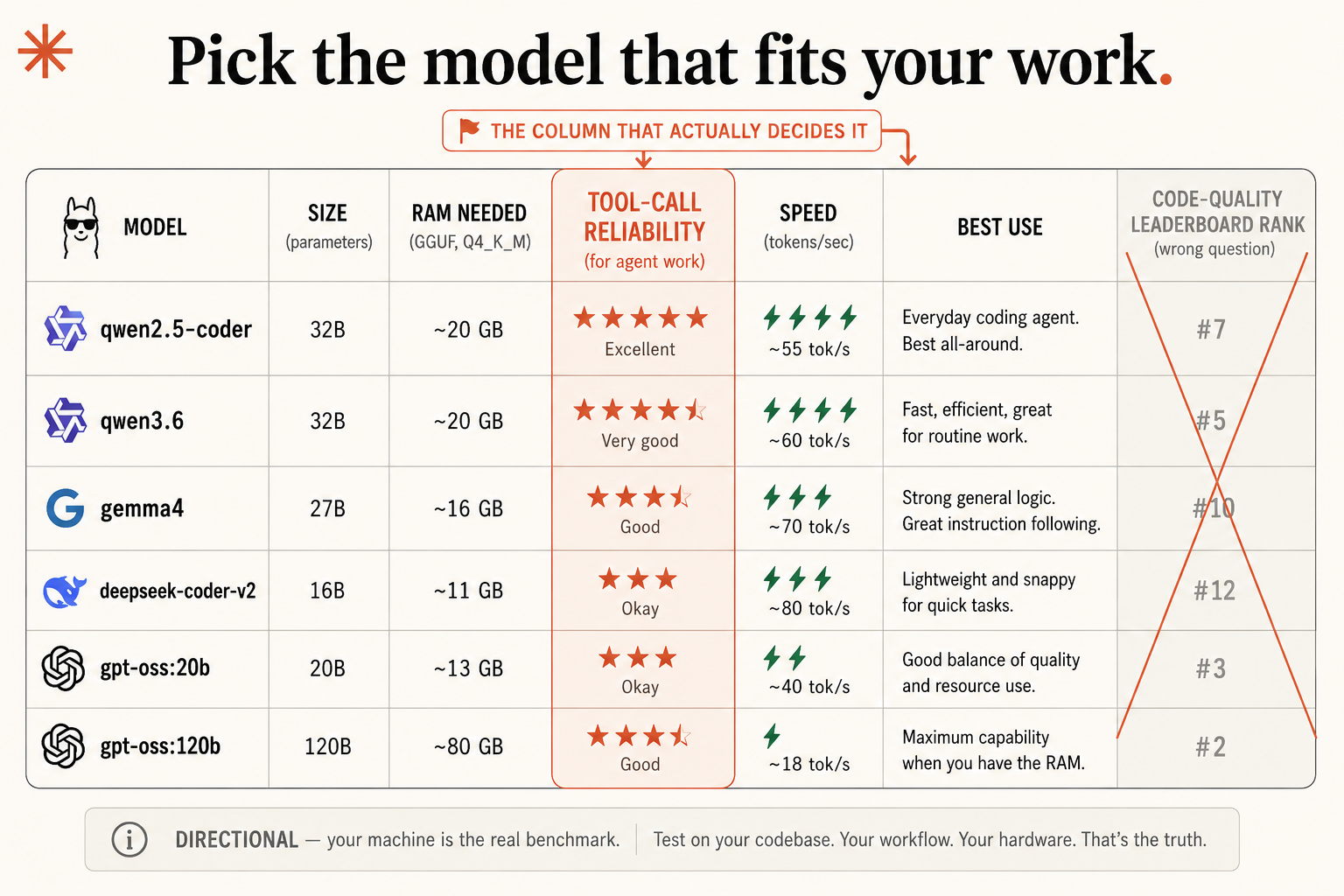
The six models worth knowing, by the column that decides it
Here’s the field of local coding models, with the honest caveat the table itself carries: these numbers are directional, not measured on your hardware. Treat it as a shopping guide. Your own benchmark is the real source of truth.
| Model | Params | RAM (Q4_K_M) | Tool-call reliability (agent work) | Speed | Code-quality rank (the wrong column) |
|---|---|---|---|---|---|
| qwen2.5-coder | 32B | ~20 GB | Excellent (5/5) | ~55 tok/s | #7 |
| qwen3.6 | 32B | ~20 GB | Very good (4.5/5) | ~60 tok/s | #5 |
| gemma3 | 27B | ~16 GB | Good (3.5/5) | ~45 tok/s | #12 |
| deepseek-coder-v2 | 16B | ~11 GB | Okay (3/5) | ~80 tok/s | #18 |
| gpt-oss:20b | 20B | ~14 GB | Okay (3.5/5) | ~40 tok/s | #3 |
| gpt-oss:120b | 120B | ~80 GB | Very good (4/5) | ~18 tok/s | #2 |
Read the last column and then ignore it. The leaderboard rank is the column most people pick on, and it’s the wrong one. gpt-oss:20b ranks #3 on code quality and is only okay in an agent loop; qwen2.5-coder ranks #7 and is the most reliable model in the table for actual agent work. The column that actually decides it is tool-call reliability. Match it to the best-use, not the rank:
- qwen2.5-coder: everyday agent, best all-around. Your baseline.
- qwen3.6: fast, efficient, great for routine work.
- gemma3: strong general logic, decent instruction-following.
- deepseek-coder-v2: lightweight and snappy for quick tasks.
- gpt-oss:20b: good balance of quality and throughput.
- gpt-oss:120b: maximum capability when you have the RAM.
Are these models even real? Verify the slugs
Local tooling fails loudly on a misspelled slug, so confirm the exact names before you pull. These three are published and current on Ollama’s library:
ollama run qwen2.5-coder # 0.5b / 1.5b / 3b / 7b / 14b / 32b (default 4.7GB)
ollama run gemma3 # 270m / 1b / 4b / 12b / 27b (default 3.3GB)
ollama run deepseek-coder-v2 # 16b / 236b (default 8.9GB)Source: ollama.com/library. The size after the colon is a real choice, not decoration: the same family can be a great pick or a terrible one depending purely on the tag. A 32B model might be brilliant and unusably slow on your laptop while the 7B of the identical family is a touch less sharp and perfectly snappy. When you compare models, hold the size roughly constant, or you’re comparing sizes wearing different names.
How do you actually pick? Benchmark on your own machine
Your own benchmark beats any table, and it’s the only model recommendation that will ever be truly yours. Pull two or three contenders and run one fixed task across all of them:
ollama pull qwen2.5-coder
ollama pull qwen3.6
ollama pull gemma3Write down one real, slightly-multi-step task and keep it identical across every model: “find the function that parses dates, add handling for null and malformed input, and write three tests for it.” Then run it on each, switching the model with the -m flag and timing the wall clock:
codex --oss --local-provider ollama -m qwen2.5-coder # then -m qwen3.6, then -m gemma3Score two things per run: seconds to complete, and an honest pass / partial / fail on correctness. The one result that should make you keep looking is a model that was fast but kept stumbling through tool calls and needing rescue. That’s the leaderboard trap showing up in your own data, and it’s exactly the model to reject no matter how good its code looked, because you’ll spend your day babysitting it.
What should you actually do?
- If you just want a working model today, run
qwen2.5-coderand stop. For a huge number of developers, the baseline is the final answer. - If your machine is modest, pick a smaller, faster model that’s plenty smart for green-zone work over the biggest one that technically loads. Speed is what you feel a hundred times a day.
- If two models tie on correctness, take the faster one, every time.
The bottom line
- Tool-call reliability beats leaderboard rank for agent work. Pick on the column that decides it, not the one everyone quotes.
- The baseline winning is not a consolation prize.
qwen2.5-coderusually deserves to win, and there’s no shame in it. - Name a primary and a fallback, set the primary as your default, and stop re-choosing every session. An undecided default is friction that sends you back to the cloud.
Frequently Asked Questions
What's the best local LLM for coding right now?+
For most people, qwen2.5-coder. It's coding-specialized, runs on modest RAM, and is steady in agent loops. Treat it as your baseline and only switch if a contender clearly beats it on your own tasks.
Why doesn't the top leaderboard model work best in my coding agent?+
Leaderboards measure one-shot code quality. An agent runs a long chain of tool calls, and the skill that matters there is tool-call reliability, which leaderboards barely test.
How much RAM do I need to run a local coding model?+
A 7B model at q4_K_M runs comfortably in 16GB. A 14B wants about 32GB. The 32B and 120B models need a GPU box or large unified memory.