What Is an Agent Harness? The 7 Layers
What is an agent harness? The 7 layers wrapped around the model: loop, context, guardrails, tools, verification, recovery, orchestration. With a teardown table.
>This names the seven layers. Agentic Coding: Build the Harness has you build every one of them in Python, layer by layer, into one running agent.

Agentic Coding: Build the Harness
The Loop, Guardrails, and Verification That Make Your AI Coding Agent Reliable on Real Code, Not Just Demos
Summary:
- An agent harness is the seven layers wrapped around a language model that turn it into a working agent.
- The layers, in build order: loop, context, guardrails, tools, verification, recovery, orchestration.
- Each layer has one job and one specific failure it prevents.
- Once you know the seven, you can take any agent apart and name what it built and what it skipped.
What is an agent harness? An agent harness is everything wrapped around a language model that turns it from a thing that predicts text into a thing that does the work. Strip all of it away and you are holding an API that autocompletes. The model is the small core. The harness is the body around it, and it is roughly 98% of what makes a tool like Claude Code feel smart. The model came in at under 2%.
The people who maintain the curated best-of-Agent-Harnesses list put the distinction cleanly:
A model answers; an agent acts. An agent harness is the runtime that turns one into the other: the model thinks; the harness decides what that thinking is allowed to touch.
The seven layers
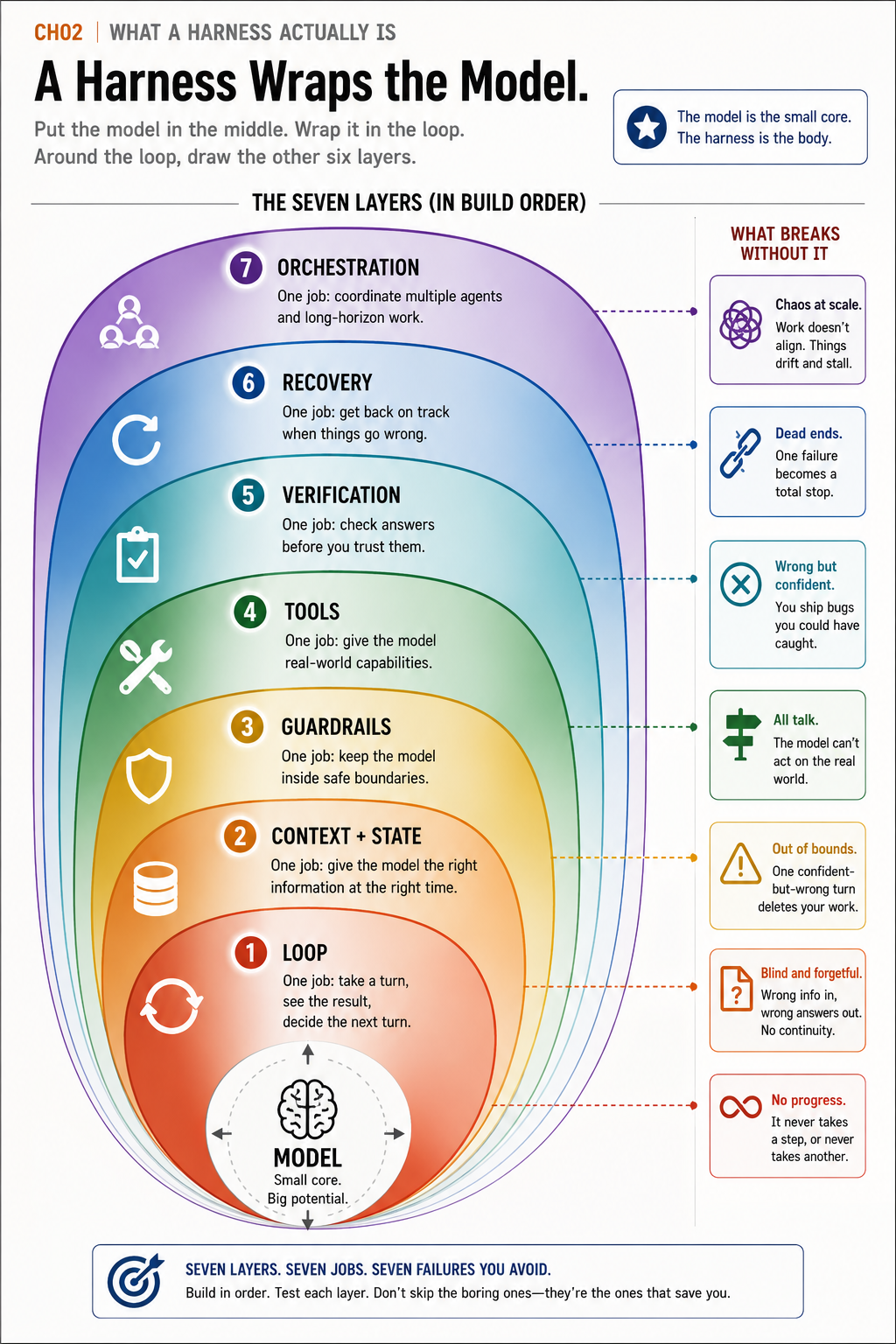
A working harness has seven layers. Read the third column as the symptom you will actually see when that layer is missing, because that is how you use this table in practice: a symptom shows up, and you flip back here to name the layer that caused it.
| # | Layer | The one job it does | What breaks without it |
|---|---|---|---|
| 1 | Loop | Take a turn, run the tool it asks for, feed the result back, repeat until done | No progress. A chatbot that describes the work instead of doing it |
| 2 | Context + state | Put the right information in the window each turn, and remember across a long task | Blind and forgetful. Loses the plot by turn three, re-reads the same file |
| 3 | Guardrails | Keep the model inside safe boundaries; gate the dangerous actions | Out of bounds. One confident-but-wrong turn deletes your work |
| 4 | Tools | Give the model real capabilities: narrow, typed, safe to retry | All talk. The smartest model flails on a vague error or a mega-tool |
| 5 | Verification | Check the answer before you trust it: tests, types, an independent look | Wrong but confident. A green-tests merged PR still ships a bug |
| 6 | Recovery | Get back on track when a check fails: roll back, retry, or escalate | Dead ends. One failed step poisons the whole run |
| 7 | Orchestration | Coordinate more than one agent on a job and merge their results | Chaos at scale. Every agent works alone, blind to the others |
Two rows carry the most weight. Guardrails are where most people are wrong about agent security: the real attack surface is not a cleverly worded prompt, it is the plain list of things the tools are allowed to touch. And tools decide whether the model ever gets anywhere, because a bad tool is the single most common reason an agent gets stuck.
One thing is not a layer but runs through all seven: evaluation. It is the discipline that measures whether any layer earns its place. Add a layer because a video told you to and you are guessing. Add a layer, measure, and rip it out if the number does not move, and you are engineering.
The vocabulary, resolved
People throw these words around as synonyms and then wonder why nothing they read fits together. They stack. Each one contains the one below it.
- Prompt. A single message you send the model. One turn of text. The smallest unit.
- Context. Everything the model can see on one call: the prompt, the system instructions, the history, any files you injected. The model knows only what is in here.
- Tool call. The model asking, in text, to run something. Your code does the actual running.
- Loop. The model and its tools cycling: call, run a tool, feed the result back, repeat until done. This is the exact line where a chatbot becomes an agent.
- Orchestration. Coordinating more than one harness on a single job.
Two words people expect on that ladder are not rungs. RAG is a technique that fills the context layer. MCP is a standard connector that plugs tools into the tool layer. Both are tactics applied to layers you already have names for, not new kinds of thing.
Drop any tool into the seven slots
The anatomy is universal, which is the proof it is real. Take three tools you have probably used and watch them fall into the same seven slots.
| Layer | Claude Code | Codex CLI | Cursor |
|---|---|---|---|
| Loop | Polished CLI loop | Same loop, terminal | Loop inside the editor |
| Context | Aggressive context mgmt | Per-session context | Managed as you move through files |
| Guardrails | Permission system gates calls | Sandbox flag + approval policy | Edit/approve prompts |
| Tools | Curated tool set | Curated tool set | File + terminal + checks |
| Verification | Verification hooks | Test/lint on request | Runs checks |
| Recovery | Retries on failure | Retries on failure | Retries on failure |
| Orchestration | Sub-agents | Sub-agents | Editor-side coordination |
The category is real and crowded. Here are named harnesses people actually run, read off the curated ranking:
| Harness | What it is |
|---|---|
| Codex | OpenAI’s terminal coding agent; sandboxed tool-call loop, multi-provider |
| opencode | Model-agnostic terminal coding agent; tool-calling loop in the shell |
| Gemini CLI | Google’s terminal coding agent |
| crush | Charm’s terminal coding agent; tool-calling loop with session persistence |
| goose | Block’s open-source terminal agent harness with recipes |
| OpenHands | Dockerized software-engineering agent; bash/editor/browser toolset |
Score any harness against the seven layers
The fastest way to understand a tool is to take it apart. One point per layer it implements, then let the total predict which setup wins on the same model.
LAYERS = ["loop", "context", "guardrails", "tools",
"verification", "recovery", "orchestration"]
def score(have): # have = set of layers the tool implements
got = sum(layer in have for layer in LAYERS)
missing = [layer for layer in LAYERS if layer not in have]
return got, missing
# your first-night while-loop vs a full harness:
print(score({"loop"})) # (1, ['context', 'guardrails', ...])
print(score(set(LAYERS))) # (7, [])Run it on the tool you actually use. Set the layers you can point at, leave the rest out, and read the gap:
# the tool you use today. Set a layer only where you can name HOW it does it.
my_tool = {"loop", "context", "guardrails", "tools", "verification", "recovery"}
got, missing = score(my_tool)
print(f"{got}/7 layers; missing: {missing}") # 6/7 layers; missing: ['orchestration']The layer a tool leaves out is the lesson. Either the tool is closed and you have found the limit of what you can know, or it genuinely lacks that layer and you have spotted a real weakness on purpose. This is also the answer to “why is every agent just a worse Claude Code?” They wired up the same model and built one or two layers. Claude Code built all seven.
You don’t have a model problem
The most useful thing the anatomy buys you is a way to diagnose a failing agent instead of shrugging and blaming the model. Almost every complaint that sounds like “the model is dumb” is a missing layer, and now you can name it.
forgets what it was doing -> missing context layer
overwrote a file it shouldn't -> missing guardrail
repeats the same broken call -> bad tool design
reports success on broken code -> no verification
one failure derails the run -> no recoverySwap in a model twice as smart and it makes the same mistakes a little more eloquently, because none of them was an intelligence failure. They were missing machinery, and machinery is something you build.
What should you actually do?
- If you can’t define a harness in one sentence yet → memorize the seven-layer table. Draw it from memory with the model in the middle. That alone puts you ahead of most people making videos about it.
- If your agent keeps failing → stop reaching for a bigger model. Run the symptom list above and name the missing layer instead.
- If you are choosing a tool → score it against the seven layers before you commit. The one with more layers built well wins on the same model, not the one with the bigger model.
- If someone tells you MCP or a framework “is” a harness → it isn’t. MCP is one connector; a framework is a harness you adopted. Know the difference before you build on either.
The bottom line
- A harness is seven layers wrapped around a model: loop, context, guardrails, tools, verification, recovery, orchestration.
- The model is something you buy. The harness is something you get good at, and it decides the outcome.
- Learn the anatomy and you stop cargo-culting tools. You start judging them.
Frequently Asked Questions
What is an agent harness in simple terms?+
An agent harness is everything wrapped around a language model that turns it from a text predictor into something that does work: the loop, context, guardrails, tools, verification, recovery, and orchestration. The model is the engine; the harness is the rest of the car.
Is an agent harness the same as MCP or a framework?+
No. MCP is a standard way to plug tools into the tool layer, one layer of seven. A framework is a harness someone else built and you adopted. The harness is the whole machine; MCP is one connector inside it.
Why does the harness matter more than the model?+
Two engineers using the same model ship wildly different agents because the harness decides the outcome. One teardown of Claude Code estimated roughly 98% of it was harness, not model. The model is what you buy; the harness is what you get good at.