Context Engineering for AI Agents
Context engineering for AI agents: build a context layer that trims the window, pins a progress note, and survives long tasks where blind compaction fails.
>This builds the context layer. Agentic Coding: Build the Harness adds the guardrails, verification, and recovery layers that turn a coherent agent into a trustworthy one.

Agentic Coding: Build the Harness
The Loop, Guardrails, and Verification That Make Your AI Coding Agent Reliable on Real Code, Not Just Demos
Summary:
- Context engineering for AI agents is the layer that decides what enters the window each turn.
- Build it in three moves: a durable progress note, a trimmed history, and the key state pinned last.
- Blind compaction drops the one constraint that mattered; a structured handoff keeps it.
- You get a context manager that holds the thread across a long task the bare loop dropped.
Context engineering for AI agents is the layer almost nobody builds, and it is the one that separates a five-minute demo from an agent that runs for an hour. When your agent does something dumb on a long task, your instinct is “the model isn’t smart enough.” Replace that instinct with a question: what was in the window when it made that decision? Nine times out of ten the answer explains everything. The model only knows what you put in front of it, and your harness writes that briefing every single turn.
Why agents fail on context, not the model
The bare loop has a context strategy, technically. The strategy is “keep everything and hope.” Every message, every tool result, every file you ever read piles up and gets shipped back on every call. That works for three turns and falls apart on thirty, for two reasons: the window fills up and old things fall off a cliff, and long before that, the one file that matters gets buried under twenty that do not.
The people who build one of the most-used harnesses on earth say the obvious fix is not enough:
Waiting for larger context windows might seem like an obvious tactic. But context windows of all sizes will be subject to context pollution and information relevance concerns. To enable agents to work effectively across extended time horizons, we developed a few techniques: compaction, structured note-taking, and multi-agent architectures. — Anthropic, Effective context engineering for AI agents
Note what that says: a bigger window is not the cure, and compaction is only one of three techniques. The real skill is choosing what goes in the window on purpose.
What enters the window each turn
Treat the window as a desk, not a warehouse. You put on it the few papers you need for the task in front of you. Everything else stays on disk, one read_file away.
| Goes in the window this turn | Stays on disk | Why |
|---|---|---|
| System instructions | (nothing) | The job description; cheap, always needed |
| The task, restated near the top | (nothing) | The goal scrolls out of view fast; pin it |
| The 1-3 files this step touches | The other 400 files in the repo | Relevance, not completeness |
| The recent back-and-forth | The full turn-by-turn history | Recent turns carry live intent; old ones are noise |
| A short running progress note | Verbatim old tool output, whole files | The note holds the gist; the data lives in the code |
There is one finding that changes how you lay out the window. Models use information best when it is at the very beginning or the very end, and performance degrades when they have to pull something out of the middle. So the task goes near the top, the current state goes at the very bottom (the last thing the model reads before it answers), and the big pile of history sits in the middle, where it is available but not load-bearing. Most people stuff the important instruction into the middle of a wall of context and then wonder why the agent ignored it.
How to build the context layer
Step 1: give it a durable memory. A plain file the agent writes its own progress into, plus a tool that lets it.
PROGRESS_FILE = "progress.md"
def load_progress():
try:
with open(PROGRESS_FILE) as f:
return f.read()
except FileNotFoundError:
return "(nothing recorded yet)"
def update_progress(notes):
"""The agent's durable memory: what's done, what's left, decisions made."""
with open(PROGRESS_FILE, "w") as f:
f.write(notes)
return f"progress updated ({len(notes)} chars)"Register update_progress as a tool exactly like the others, so the model can call it.
Step 2: trim the history without breaking the API. Keep the system message and the task, then the most recent turns. The trap: a slice can land between an assistant message that called a tool and the tool message carrying that tool’s result. Ship the orphaned result without its parent and the API rejects the whole request.
MAX_WINDOW = 24
def trim_history(messages, keep_last=MAX_WINDOW):
if len(messages) <= keep_last + 2:
return messages
head, tail = messages[:2], messages[-keep_last:]
while tail and tail[0]["role"] == "tool":
tail = tail[1:] # its assistant turn got trimmed: drop the orphan
return head + tailThat while loop is the difference between a window builder that works and one that 400s the first time a trim lands mid-pair.
Step 3: pin the live state where the model reads best. Build the view the model actually sees: trimmed history with the progress note pinned last.
def build_window(messages):
pin = {"role": "user",
"content": "PROGRESS SO FAR (keep current with update_progress):\n"
+ load_progress()}
return trim_history(messages) + [pin]Then change one line in your loop: send build_window(messages) instead of the raw messages. The full list still grows so you keep the record, but what the model sees each turn is trimmed and progress-pinned.
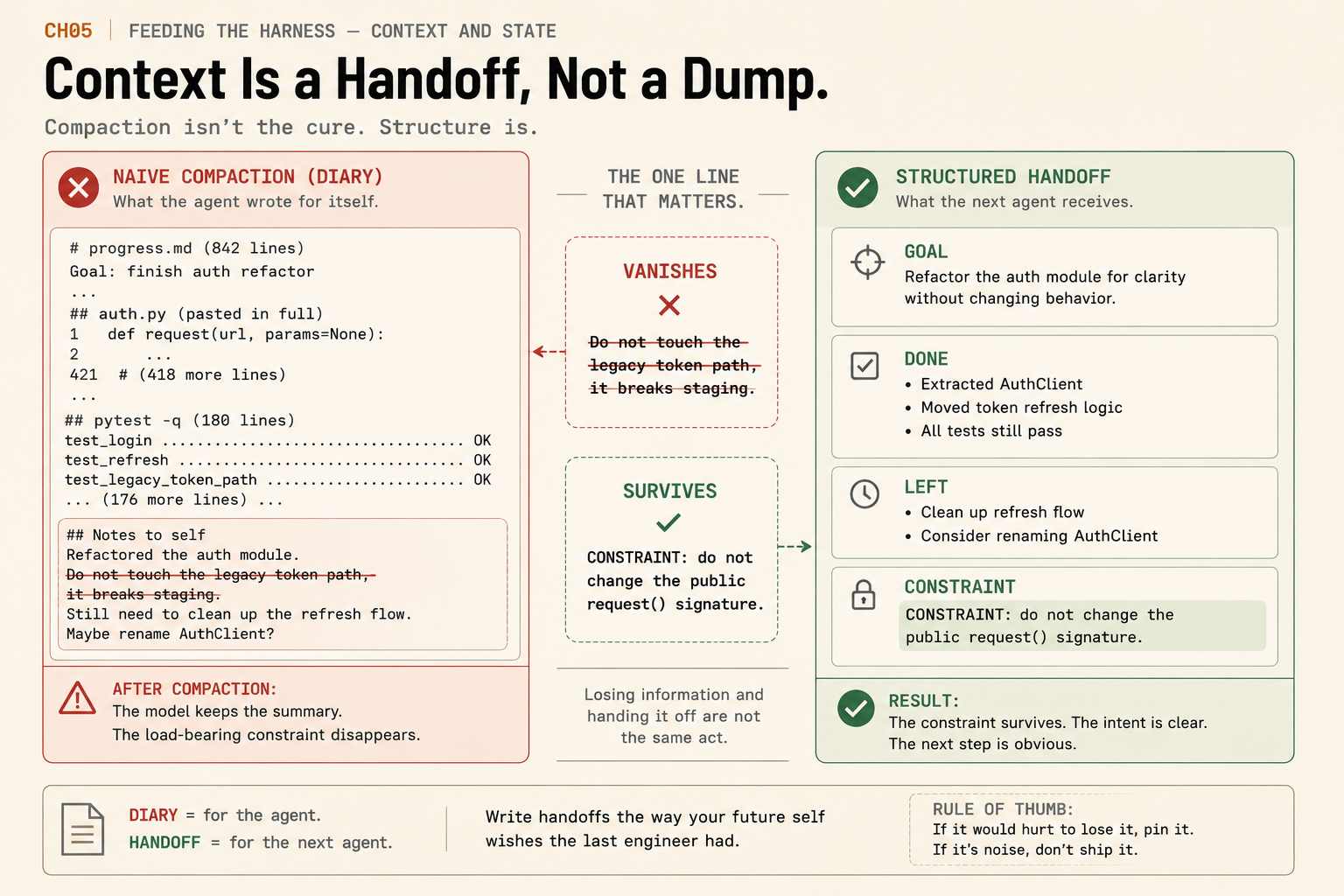
Context is a handoff, not a dump
A progress file is only as good as what the agent writes into it. Left alone, a model writes a diary that pastes in what it can already read off disk: the full file, 180 lines of pytest output, the whole history. That is the naive-compaction failure, and it loses the one thing that mattered. Steer it toward a structured handoff instead:
GOAL: add retry logic to the HTTP client, with a test.
DONE: added a 3-try backoff wrapper in http_client.py; wrote test_retry
LEFT: one failure left, test_auth fails on the expired-token case
CONSTRAINT: do not break the legacy token path, it breaks staging.The split is the whole discipline. The handoff holds the things future-you cannot reconstruct from the code: the goal, the decisions, the next step, and above all the constraints. The rule of thumb: if a constraint would break a build, it is a fact, not a footnote. Everything else (the diff, the directory listing, the 200 lines of test output) stays in the codebase, one re-read away. Losing details and handing them off are not the same act.
What broke without it
This is the failure the context layer fights, and it has a name: goal drift. The agent does not abandon the goal in one dramatic moment. It drifts, one lossy summary at a time. The constraint you gave it on turn two (“keep the public API unchanged”) gets summarized to “updated the API” gets summarized to nothing, and on turn twenty-five it changes the public API with a clear conscience.
The pinned progress file is the defense. Because the constraint lives in the file and the file rides at the end of every window, the agent reads “do not break the legacy token path” fresh every turn instead of smoothing it away one compaction at a time:
[rig] turn 3: read_file({'path': 'http_client.py'})
[rig] turn 4: update_progress({'notes': 'DONE: read http_client.py...'})
[rig] turn 9: run({'command': 'pytest -q'}) -> 12 passedNo repeat read. The file got read once, its takeaway went into the progress note, and every later turn read that note instead of re-reading the file. The bare loop would have re-read it three times and summarized the constraint into oblivion.
What should you actually do?
- If your agent re-reads the same file → add a progress note it maintains, and pin it to every window. The repeats stop because it can see what it already did.
- If your agent forgets a constraint halfway through → write the constraint into the pinned note, not the prose. Compaction drops prose; a pinned line survives.
- If you are tempted to turn on automatic compaction and call it done → don’t. Blind compaction keeps the gist and drops the specifics, and in agent work the specifics are what you were paying for.
- If you are about to buy a bigger context window to fix a long task → trim and pin first. A model handed the three files it needs beats the same model buried under forty thousand lines that happen to contain them.
The bottom line
- Most broken agents are a context problem wearing a model problem’s clothes. Fix the briefing before you upgrade the brain.
- A bigger window is not the cure. Structure is: trim the history, pin the state, put the key facts at the top and bottom.
- A well-briefed model looks like a much smarter one, and that is the cheapest reliability win you will ever ship.
Frequently Asked Questions
What is context engineering for AI agents?+
Context engineering is deciding what enters the model's window each turn and how the agent remembers across a long task. It is the layer that keeps an agent coherent instead of letting it re-read files, forget constraints, and lose the plot by turn three.
Why does my AI agent forget what it was doing?+
Because the bare loop keeps everything and ships it all back every turn until the window fills and old turns fall off a cliff. The fix is a context layer: trim the history, pin a short progress note, and put the important content where the model reads best.
Does a bigger context window fix the problem?+
No. Bigger windows still suffer context pollution, and models read the middle of a long window worst. Structured note-taking beats a larger window because it puts the load-bearing facts where the model actually attends.