How to Build Karpathy's LLM Wiki in 90 Minutes
The karpathy llm wiki is two folders and a schema file, not three folders. Build the real structure on disk in 90 minutes with the mkdir commands and 5 entries.
>This covers the first 90 minutes. Files Over Prompts goes deeper on the lint pass that catches drift before it spreads, the multi-vault split for teams, and the HTML artifact pillar that compounds on top of the wiki.

Files Over Prompts
Build HTML Artifacts and LLM Wikis Your Claude Agent Actually Reads
Summary:
- The real Karpathy structure: two folders plus a schema file (not three folders).
- The exact
mkdircommands and the CLAUDE.md schema template you paste verbatim.- Five wiki entries you ingest by lunch, one per use case.
- The “what is your role here” smoke test that proves the agent actually loaded the schema.
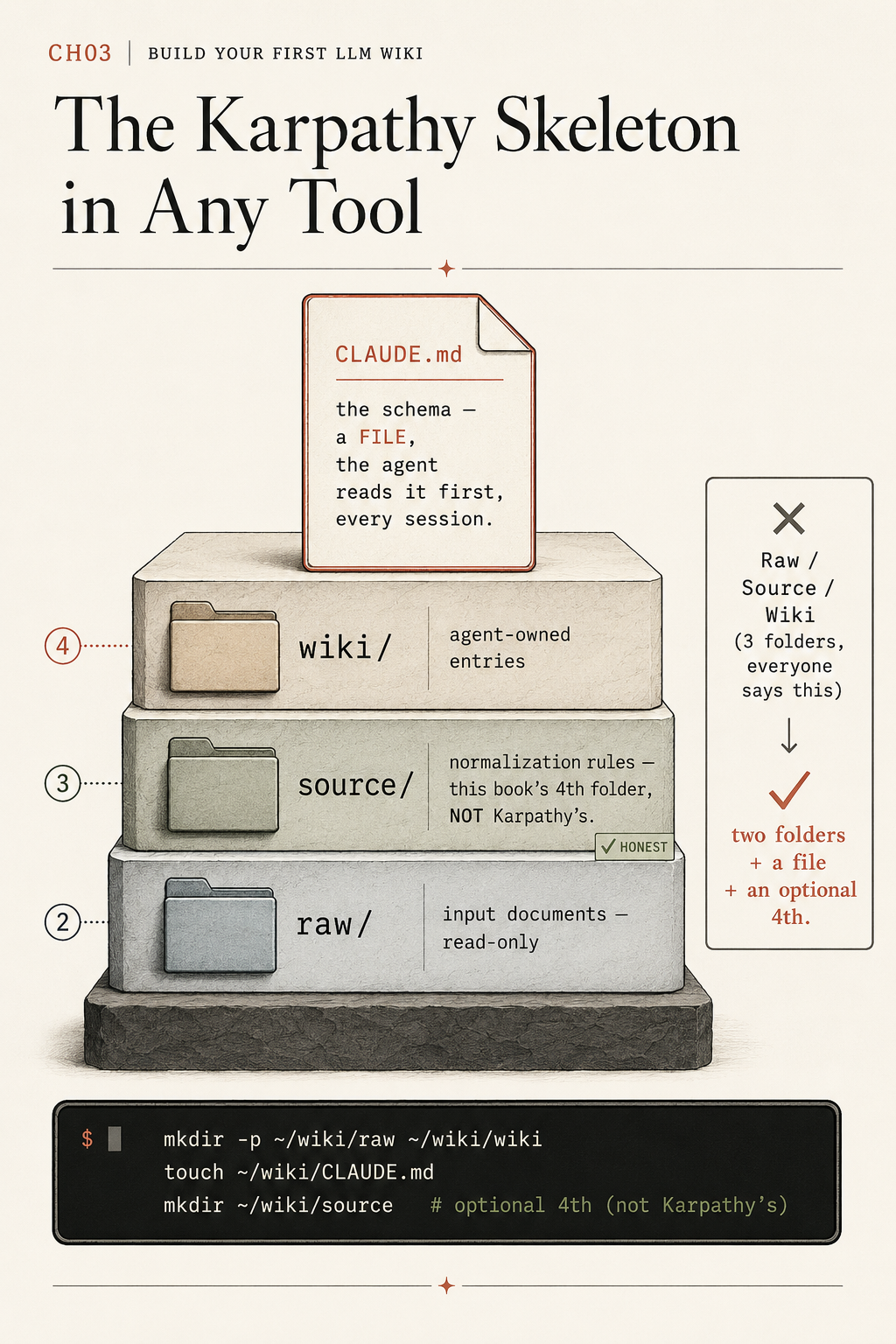
The karpathy llm wiki is the thing everyone has heard of and nobody got right. Almost every blog post about it sets up three folders called Raw, Source, and Wiki. That layout is wrong, and the wrong piece is the piece holding the whole structure up. The agent reads first, and what it reads first determines whether your wiki works. The actual structure is two folders and a file. By the end of this 90 minutes you have it on disk and the agent is using it.
What is Karpathy’s LLM wiki actually?
The LLM wiki is a folder you write for the agent, not for yourself. Karpathy’s llm-wiki.md gist (5,000+ stars) names three layers, and the third layer is the part the internet keeps mangling.
Layer one is Raw sources: your curated source documents (articles, papers, images, data files). The LLM reads them and never modifies them. This is the source of truth.
Layer two is The wiki: a directory of LLM-generated markdown files. Summaries, entity pages, concept pages, comparisons, an overview, a synthesis. The LLM owns this layer entirely and writes it. You read it.
Layer three is The schema. Karpathy’s verbatim definition:
The schema: a document (e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex) that tells the LLM how the wiki is structured, what the conventions are, and what workflows to follow when ingesting sources, answering questions, or maintaining the wiki.
Read that twice. The schema is a file. Singular. One markdown file at the root of your folder. Not a “Source” folder. Not a third directory. A file called CLAUDE.md if you run Claude Code, AGENTS.md if you run Codex or OpenCode.
The same files do two opposite jobs. You read them as notes. The agent reads them first, every session. Same folder, opposite direction. That is the inversion the wiki layer makes possible.
What is the right folder structure on disk?
Two folders plus a file. Open a terminal and run:
mkdir -p ~/wiki/raw ~/wiki/wiki
touch ~/wiki/CLAUDE.mdThat is the entire Karpathy structure. raw/ holds input documents you never edit. wiki/ holds the agent-generated entries it both reads and writes. CLAUDE.md at the root is the schema, and the schema is a file, not a folder.
If you have read three articles about Karpathy’s gist and you are running the three-folder version, this is where you fix it. The “Raw / Source / Wiki” framing is on Reddit, in at least two YouTube summaries with six-figure view counts, and in the strategist notes for the book this article is from before the author corrected himself. The folder you do not need is the middle one. The file you do need is the schema.
There is an optional fourth folder most readers add by week two:
mkdir ~/wiki/source # optional 4th (this book's extension, not Karpathy's)source/ holds normalization templates, small prompt files the agent reads before ingesting raw documents. The folder is not in the gist. The book recommends it because every reader who runs the two-folder version for a month ends up wanting a place to put their ingest prompts. If you want to stay strictly inside the gist, skip the fourth folder and inline the prompts at the top of CLAUDE.md instead.
What goes in the CLAUDE.md schema file?
The schema is the agent’s user manual for your wiki. Open ~/wiki/CLAUDE.md and paste this template. Edit the bracketed lines:
# Wiki schema
This directory is a Personal AI OS following the Karpathy llm-wiki pattern.
## Layout
- raw/ Read-only input documents (PDFs, transcripts, articles).
- wiki/ Agent-owned markdown entries. You both read and write these.
- source/ Normalization templates the agent reads before ingesting raw.
- This file (CLAUDE.md) is the schema.
## Conventions
- Wiki entry filenames are kebab-case and prefixed by type: account-*, concept-*, issue-*, module-*, person-*.
- Every wiki entry has a frontmatter block with `type`, `source-path`, and `ingested-at`.
- Cross-references use [[wiki/<canonical-filename>]] not free-form aliases.
## Session start
On every new session:
1. Read wiki/index.md (if it exists).
2. Ask me which of the five use cases this session is about (PKM, sales, support, code review, research).
3. Wait for me to name an entry or a raw file before reading deeply.
## When ingesting
- Read source/wiki-ingest.md first.
- Read the named raw file.
- Produce the wiki entry.
- Update wiki/index.md with the new entry's link.Save the file. Start a fresh Claude Code session in ~/wiki/. Type one sentence: “What is your role here?” The agent should paraphrase the schema. If it does not, the file name is wrong (must be exactly CLAUDE.md, case-sensitive on Linux), you are not in the right directory, or the file is nested instead of at the project root.
Claude Code loads CLAUDE.md at four scopes in this order:
| Scope | Path | Use case |
|---|---|---|
| Managed | /Library/Application Support/ClaudeCode/CLAUDE.md (macOS) and equivalents | Organization-wide instructions from IT or DevOps |
| User | ~/.claude/CLAUDE.md | Your personal preferences across every project |
| Project | ./CLAUDE.md or ./.claude/CLAUDE.md | Team-shared instructions for one project (this is your wiki schema) |
| Local | ./CLAUDE.local.md | Personal project-specific overrides; .gitignore this |
Source: Claude Code memory documentation. The Anthropic docs note that scopes load “from broadest scope to most specific, so a project instruction appears in context after a user instruction.” Your wiki schema sits at the Project scope and gets committed to git like any other config file. That is also one of the most-misreported facts about Claude Code: most posts that mention CLAUDE.md scopes call it three, not four. The Local scope is the one most people skip.
How do you ingest your first five wiki entries?
Before you ingest anything, save the ingest prompt template to ~/wiki/source/wiki-ingest.md:
You are turning a raw input document into a wiki entry.
The wiki entry will live at: wiki/<kebab-case-filename>.md.
The wiki entry MUST:
- Open with a single H1 stating the canonical subject.
- Include a frontmatter block with: type, source-path, ingested-at.
- Use one fact per line where facts can be enumerated.
- Use explicit named anchors (account names, concept names) not metaphors.
- End with a "Open questions" section that lists what the source does not answer.
DO NOT:
- Copy raw quotes longer than 2 sentences from the source.
- Use first-person voice; the wiki is the agent's notes, not the human's.
- Invent facts not in the source.
Source path: <RAW_PATH>
Source type: <prospect-transcript | paper-abstract | ticket-archive | pr-description | personal-note>Now ingest one entry per use case so the framework gets stress-tested across five domains. The point of five is not that you need five. The point is that the wiki layer is application-agnostic and the only way to trust that is to see it work in more than one domain.
- PKM. Pick a podcast or article you want to retain. Save the show notes as
~/wiki/raw/<slug>.md. Prompt Claude Code: “Readsource/wiki-ingest.md. Readraw/<slug>.md. Source type is personal-note. Write the wiki entry towiki/concept-<topic>.md.” - Sales. Take a sales call transcript. Save as
~/wiki/raw/discovery-<account>.md. Source type:prospect-transcript. Output:wiki/account-<name>.md. The agent compresses a thousand-word transcript into a six-bullet structured profile (Account, Contact, ICP signal, Constraint, Next action). - Support. Pull three recent tickets. Save as
~/wiki/raw/tickets-<cluster>.md. Source type:ticket-archive. Output:wiki/issue-<symptom>.md. The agent produces one recurring-issue summary, not three ticket re-pastes. - Code review. Copy a PR description from any public repo. Save as
~/wiki/raw/pr-<number>.md. Source type:pr-description. Output:wiki/module-<name>.md. The agent infers a module map, not a PR summary. - Research. Pick a paper abstract. Save as
~/wiki/raw/abstract-<arxiv-id>.md. Source type:paper-abstract. Output:wiki/concept-<topic>.md. The agent records what the paper changes for you, not the paper.
The work is the curation. The ingest is the agent’s job.
What broke when I ran this the first time?
The first time I ran the BUILD STEP, three of my five entries were structurally bad and I did not catch it until ten days later when the agent gave me wrong answers about my own pipeline. Each defect has a named pattern.
Over-summarization in PKM. I compressed a forty-five-minute podcast to three bullets. Two weeks later the agent confidently quoted a line that was not in the show. The bullet "prefers EPUB" was true; everything around it was filled in. The fix: leave the gaps visible. Write “EPUB section: 15 minutes, three points made, see raw for full quote”, not a one-bullet compression. The agent then knows when to fetch the raw.
Missing next-action in sales. My first account entry had ICP, contact, budget constraint. It did not have what I had committed to send by Friday. The agent could describe Acme on Monday morning but could not answer the question that mattered. Fix: every sales entry’s last line is "Next action: <verb> <owner> <deadline>". If you cannot fill that line, the entry is not ready to graduate from raw to wiki.
Raw transcript leak in support. The first support entry had the five structured lines plus a half-page of paraphrased ticket prose below them. The agent spent half its context on the prose. Fix: the ingest prompt enforces “do not copy raw quotes longer than 2 sentences”. Re-ingest with that rule and the entry tightens.
If two of five entries fail on first pass, that is normal. Re-ingest the two with a tighter prompt. The cost of one re-ingest is cents. The cost of a structurally bad entry surfacing in a real meeting two months from now is a confidently wrong answer.
What should you actually do?
- If you have an existing Obsidian vault → do not move anything. Build
~/wiki/parallel to it. The wiki layer is additive, not destructive. - If you have not picked a substrate → use plain markdown files. Add Obsidian on top later if you want the graph view. The directory structure does not change when the substrate changes.
- If you are on a team → start single-vault this weekend. The multi-vault split (personal / customer / engineering) is the next chapter, not this one.
- If your
"What is your role here?"test failed → check the file name, the case, and that you started Claude Code in~/wiki/. The schema only loads at the project root.
bottom_line
- The Karpathy wiki is two folders and a file. Not three folders. The schema is a file. If you set up three folders you built it wrong and the agent will not know it.
- Ship the structure in 90 minutes. Five entries by lunch. The five-domain test is what makes you trust that the framework is not domain-specific.
- The agent reads first. The schema you write today is the thing that fires on every session next Tuesday morning. That is the whole bet.
Frequently Asked Questions
What is Karpathy's LLM wiki actually?+
Two folders and a schema file. A `raw/` folder for source documents the agent reads but never modifies, a `wiki/` folder of agent-generated markdown summaries, and a `CLAUDE.md` schema file at the root that tells the agent how to use both. The schema is a file, not a third folder. Most blog posts get this wrong.
Do I need Obsidian or Notion to build this?+
No. The substrate is files on disk. Plain markdown works. Obsidian gives you a graph view on top. Notion works if you accept the cross-system friction. Pick whatever editor you already use and point it at the folder.
How long does the first wiki actually take to build?+
About 90 minutes if you have Claude Code installed. Two minutes for the mkdir commands, forty minutes to write the schema file, and an hour to ingest five raw sources into five wiki entries the agent can read back.