Claude Code Token Cost: Why One Session Hit $40
The claude code token cost math behind a $40.78 receipt: 12.8M tokens, the 90% cache toggle that makes it $3.84, and the framework that takes it to $1.83.
>Build TradingView Signals with Claude Code ships the full token budget plus the RAG setup and four-part framework that produce the $1.83 session, not the $40 one.
Build TradingView Signals with Claude Code
Ship Pine v6 Indicators, Alerts, Backtests & Webhooks This Weekend
Summary:
- Breaks down the real claude code token cost behind the $40.78 receipt that became this book’s running case study.
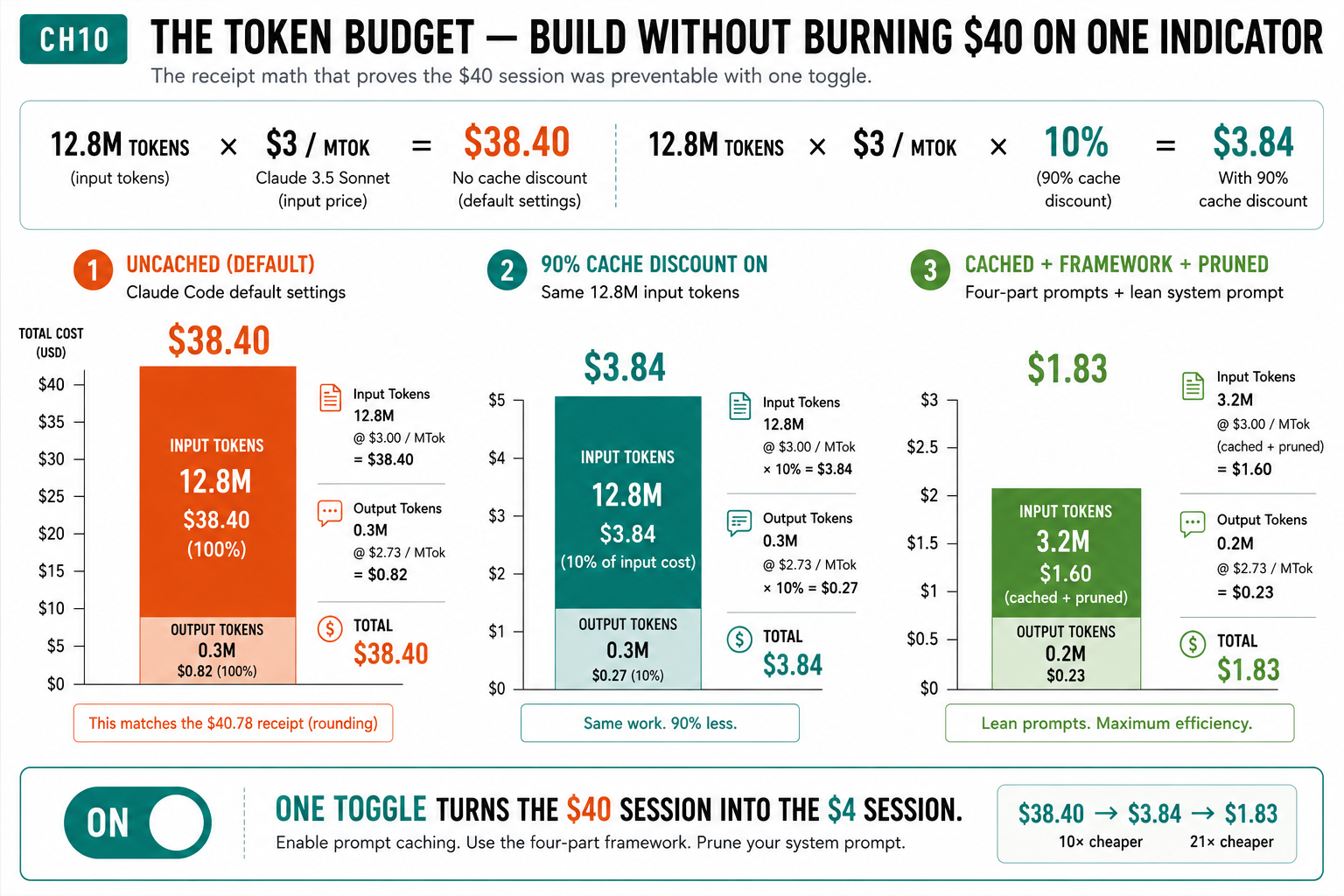
- The same 12.8M-token job costs $38.40 uncached, $3.84 with the cache toggle, $1.83 cached plus framework plus a pruned system prompt.
- Caching is the dominant lever; free models and smaller models are not.
- Deliverable: the three-scenario cost table and the commands that prove the cache is working.
The claude code token cost that scared an entire subreddit was one receipt: $40.78 for a single session, 12.8 million input tokens, 611 lines of code changed. The post got 177 upvotes and the top reply asked the only question that mattered: why doesn’t the model do this to save tokens? It does not, because there is no frugal-mode toggle. Token efficiency is a workflow you engineer. The good news is the math is simple and the dominant fix is one setting.
What did $40 actually buy?
Nothing that had to cost $40. The session burned 12.8M input tokens because every turn fed the whole script back into context and triggered another full rewrite. The math, at Sonnet’s $3 per million input tokens:
| Scenario | Input | Output | Total |
|---|---|---|---|
| 1. Uncached (default) | 12.8M x $3/MTok = $38.40 | 0.3M = $0.40 | $38.40 |
| 2. 90% cache discount on | 12.8M x $3/MTok x 10% = $3.84 | 0.3M = $0.40 | $3.84 |
| 3. Cached + framework + pruned | 2.3M = $1.60 | 0.2M = $0.23 | $1.83 |
Scenario 1 matches the $40.78 receipt within rounding. Scenario 2 is the same 12.8M tokens with one setting changed: 9.x times cheaper. Scenario 3 is the realistic engineered session: 21x cheaper than the default. Same work. The difference is entirely workflow.
The dominant lever is caching, not free models
Most “Claude Code is expensive” advice tells you to use free models or smaller models. That is the small lever. The dominant lever is prompt caching on a stable preamble. From the official prompt-caching docs:
| Token type | Multiplier vs. base input price |
|---|---|
| 5-minute cache write | 1.25x the base input price |
| 1-hour cache write | 2x the base input price |
| Cache read | 0.1x the base input price |
(Anthropic prompt caching docs.) The cache read at 0.1x is the 90% discount. Your CLAUDE.md plus the imported Pine docs is a large, stable preamble that appears at the start of every prompt in a session. Cache it once, and every subsequent prompt reads it at a tenth of the price. That single mechanism is the $38.40 → $3.84 jump in the table. The docs also note shorter prompts cannot be cached at all, which is why the preamble has to be substantial and stable to qualify.
Verify it is actually firing:
claude --debug 2>&1 | grep -i cacheThe first session shows cache_creation_input_tokens. Subsequent sessions within the cache window show cache_read_input_tokens at the 10% rate. If you only ever see creation tokens, your preamble is changing between sessions and invalidating the cache.
What takes it from $3.84 to $1.83
Scenario 3 stacks two more patterns on top of caching.
System-prompt pruning. The default Claude Code system prompt is a generalist preamble covering Python, web, data engineering. For Pine-only work most of it is tokens you pay for and learn nothing from. A user on r/ClaudeCode put it bluntly with 425 upvotes: stop using the default system prompt, it tries to do everything and fails on all sides. Replace it with a Pine-only one:
claude --system-prompt "$(cat ~/projects/pine-claude/system-prompts/pine-only.md)"The default runs roughly 3,000 tokens; a Pine-only equivalent runs about 800. That is ~2,200 input tokens saved per turn, before caching.
The four-part framework. Tight Goal / Constraint / Verification / Output prompts at 200-400 tokens each, instead of unconstrained prompts that page the whole file back every turn. This is what drops Scenario 3’s input from 12.8M to 2.3M tokens. The framework is a cost optimization as much as a quality one.
Check the session total at the end:
/costA cached, framed, pruned RSI-confluence rebuild lands around $0.05-$0.10, not $40.
The cheapest pattern is your keyboard
The $40 session contained at least eight micro-tasks Claude was asked to do that a chartist could have typed in 90 seconds total, each costing about $1.50 to prompt and receive. Type-it-yourself triggers: renaming a variable, changing an EMA period, swapping a plot color, flipping a comparison operator, toggling overlay, adjusting a shorttitle. Use Claude for the multi-file work, the doc-grounded generation, the architectural calls. Type the one-line edits. The first cheapest pattern in the stack is not Claude.
What should you actually do?
- If your bill is climbing → run
claude --debug 2>&1 | grep -i cacheand confirm cache reads are firing. Caching is the 9x lever; everything else is smaller. - If the cache never fires → you are editing CLAUDE.md mid-session or reordering imports. Keep the preamble stable; edit it only when conventions actually change.
- If you reach for a free model to save money → reconsider. Free models give 60-90% Pine quality with rate limits that fragment your work. Pay for the model, cache the preamble, prune the prompt.
- If you are prompting one-line edits → type them. About 20 micro-tasks are faster typed than prompted.
bottom_line
- The $40 session was a session that lost the plot at minute three and never recovered. The fix is not a cheaper model; it is a stable cached preamble plus tight prompts.
- Caching is the dominant lever. A 90% discount on the largest, most-repeated part of every prompt beats every other optimization combined.
- Engineered spending beats unintentional spending by 5-20x reliably. Over a year of Pine work that gap is the cost of the entire stack, several times over.
Frequently Asked Questions
Why did my Claude Code session cost $40?+
An unconstrained session pages the whole file into context every turn. 12.8M input tokens at $3 per million is $38.40 before output. The cost was the burn rate, not the work. Caching plus tight prompts make the same job a few dollars.
Does prompt caching actually reduce Claude Code cost?+
Yes, it is the dominant lever. Cache reads bill at 0.1x the base input price, a 90% discount on the cached portion. The same 12.8M tokens drop from $38.40 to about $3.84 with caching on a stable preamble.
What is the cheapest pattern in a Claude Code workflow?+
Your own keyboard. About 20 micro-tasks (renaming a variable, changing an EMA period, swapping a color) are faster to type than to prompt. The $40 session contained at least eight of them.