How to Build a Polymarket Prediction Bot with Claude
>This covers prediction market bots. Use Claude to Build an AI Trading Bot goes deeper on stock screeners, options flow trading, and Monte Carlo backtesting.
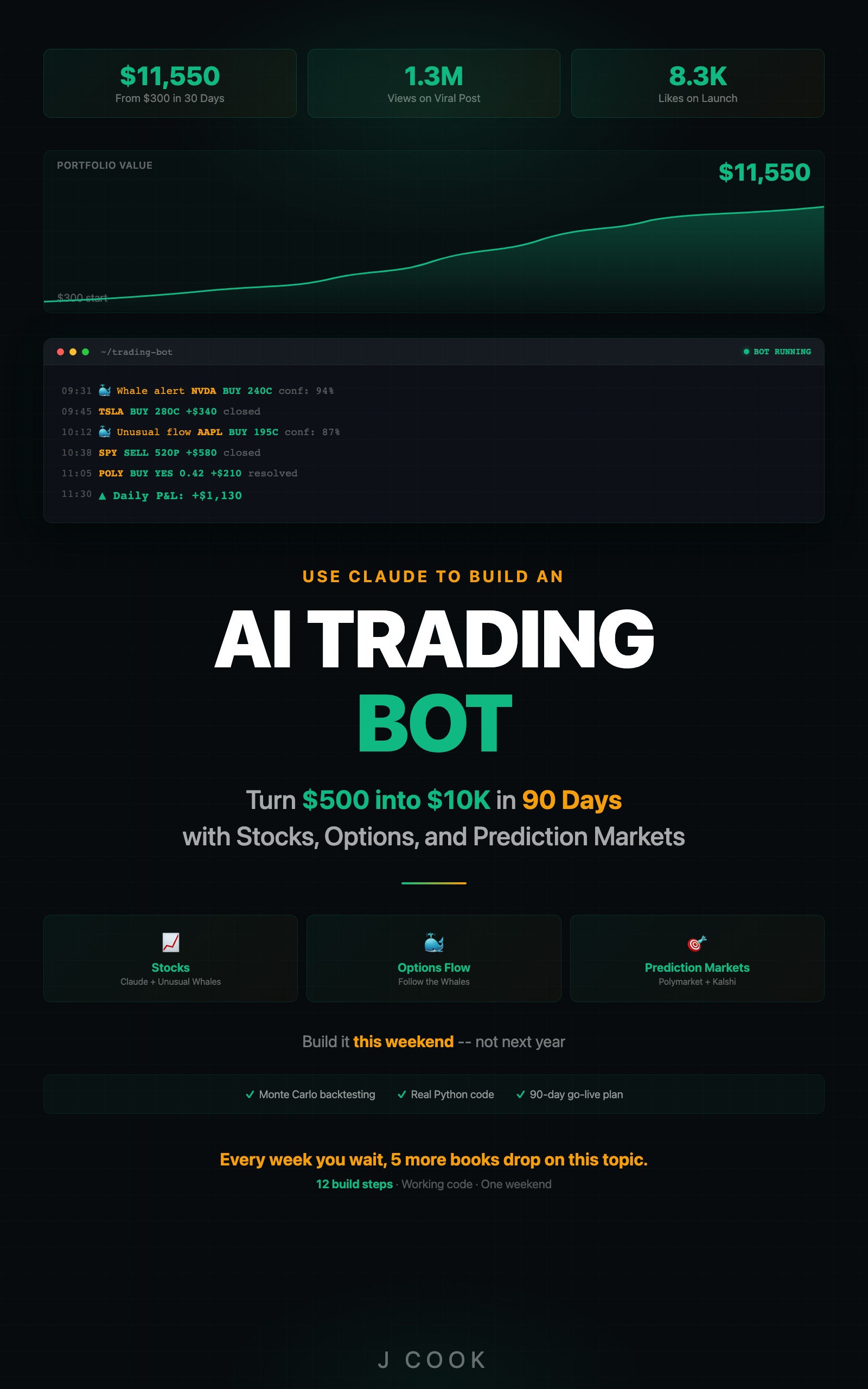
Use Claude to Build an AI Trading Bot One Weekend
Turn $500 into $10K in 90 Days with Stocks, Options, and Prediction Markets
Summary:
- Build a Python bot that fetches active Polymarket contracts and filters for analyzable questions.
- Use Claude to estimate true probabilities and calculate expected value against market prices.
- Surface mispriced bets where the probability gap exceeds 10 percentage points.
- Copy-paste expected value calculator, calibration tracker, and the edge tier ranking.
In early 2026, a contract on Polymarket asked whether the Federal Reserve would cut rates at its March meeting. The market priced it at 22 cents. Claude estimated 41% after processing 14 Fed governor speeches, three inflation reports, and two employment data releases. I bought 500 shares at $0.22 each. Total cost: $110. The contract settled at $1.00. My $110 became $500.
Claude read the actual data. The crowd was reacting to headlines. That gap? That is where the money is.
Why does Claude have an edge on prediction markets?

Stock trading pits Claude against hedge funds running their own AI systems. Prediction markets pit Claude against people who bet $50 based on a tweet they read at lunch. The analytical bar is low.
Most Polymarket bettors have not read the Cleveland Fed’s inflation nowcast. They cannot calculate CPI base effects. They bet on vibes. Claude does the math.
Three specific advantages:
- Data processing. Claude synthesizes analyst consensus, revenue trends, sector performance, and management guidance faster than any individual bettor.
- Bias correction. Political markets are full of wishful thinking. People bet on what they want to happen. Claude has no political opinions.
- Multi-source synthesis. A single contract depends on economic data, political dynamics, and historical base rates. Claude holds all inputs simultaneously.
How does the prediction bot work?
The bot runs once or twice daily. Five steps:
- Fetch active contracts from the Polymarket API (Gamma endpoint:
https://gamma-api.polymarket.com/markets) - Filter for analyzable contracts (economic data, corporate events, political events with polls)
- Ask Claude to estimate the true probability for each contract
- Calculate expected value:
EV = (estimated_prob * $1.00) - market_price - Bet on contracts where the gap exceeds 10 percentage points
import os
import json
import requests
from dotenv import load_dotenv
from anthropic import Anthropic
load_dotenv()
claude = Anthropic()
POLYMARKET_API = "https://gamma-api.polymarket.com"
MIN_GAP = 0.10 # 10% minimum probability gap
def get_active_markets():
"""Fetch active Polymarket contracts."""
try:
resp = requests.get(f"{POLYMARKET_API}/markets",
params={"active": "true", "limit": 50,
"order": "volume24hr"})
return resp.json() if resp.status_code == 200 else []
except Exception as e:
print(f"API error: {e}")
return []
def estimate_probability(question, market_price):
"""Ask Claude to estimate the true probability."""
response = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=800,
messages=[{
"role": "user",
"content": f"""PREDICTION MARKET ANALYSIS
Question: {question}
Current market price: {market_price} ({market_price*100:.0f}% implied)
Research this question:
1. What does the most recent relevant data say?
2. What do expert forecasts or polls suggest?
3. Historical base rate for similar events?
4. Biases likely affecting the market price?
Return JSON:
{{
"estimated_probability": 0.XX,
"confidence": "HIGH" or "MEDIUM" or "LOW",
"reasoning": "2-3 sentences with specific data points",
"key_data": ["point 1", "point 2", "point 3"]
}}
Be calibrated. If the market price looks correct, say so."""
}]
)
try:
return json.loads(response.content[0].text)
except json.JSONDecodeError:
text = response.content[0].text
if "```" in text:
text = text.split("```")[1]
if text.startswith("json"):
text = text[4:]
return json.loads(text.strip())The prompt explicitly says “Be calibrated. If the market price looks correct, say so.” Without this, Claude tends to disagree with the market on everything. You want it to find real gaps, not manufacture disagreement.
How do you calculate expected value?
def calculate_ev(estimated_prob, market_price):
"""Calculate expected value for YES and NO sides.
estimated_prob: Claude's probability estimate (0-1)
market_price: current YES contract price (0-1)
Returns: dict with side, EV, and gap
"""
ev_yes = (estimated_prob * 1.0) - market_price
ev_no = ((1 - estimated_prob) * 1.0) - (1 - market_price)
if ev_yes > ev_no and ev_yes > 0:
return {"side": "YES", "ev": ev_yes,
"gap": estimated_prob - market_price}
elif ev_no > 0:
return {"side": "NO", "ev": ev_no,
"gap": (1 - estimated_prob) - (1 - market_price)}
return {"side": "SKIP", "ev": 0, "gap": 0}
# Example: Claude says 52%, market says 35%
result = calculate_ev(0.52, 0.35)
# {'side': 'YES', 'ev': 0.17, 'gap': 0.17}
# $0.17 expected profit per share. Buy YES.A 17-cent expected value on a 35-cent contract is a 49% expected return. That is the kind of gap Claude finds on economic data contracts where the crowd is trading headlines instead of reading the actual numbers.
Where does Claude have the most edge?
Not all prediction markets are equally exploitable. Ranked by six months of tracking:
| Tier | Market Type | Avg Gap | Why |
|---|---|---|---|
| 1 | Economic data (CPI, jobs, GDP) | 8-15 pts | Claude reads leading indicators; bettors read headlines |
| 2 | Corporate earnings | 5-10 pts | Claude synthesizes consensus + trends; crowd anchors on last quarter |
| 3 | Political events with polls | 3-20 pts | Emotional betting creates wide mispricings on polarized questions |
| 4 | Crypto price targets | 2-5 pts | Sentiment-driven, hard to quantify, thin edge |
| Skip | Weather, sports, celebrity gossip | 0 pts | No data advantage. Skip entirely. |
The economic data tier is the sweet spot. When a contract asks “Will inflation be below 2.8% in the next CPI report?” most bettors have not looked at the Cleveland Fed nowcast.
What broke when I built this?
Claude overestimated its own certainty. The first version assigned HIGH confidence to almost everything and disagreed with the market on 80% of contracts. Most of those disagreements were wrong.
The fix was the calibration instruction in the prompt and adding a minimum gap threshold. If Claude’s estimate differs from the market by less than 10 percentage points, skip it. The small gaps are noise.
Do not auto-execute trades. This system generates signals, not orders. Review every signal manually before placing a trade. Automated execution on prediction markets amplifies mistakes at machine speed. The signal detector tells you where to look. You decide whether to act.
def scan_markets():
"""Run the full pipeline: fetch, estimate, filter, rank."""
markets = get_active_markets()
opportunities = []
for m in markets:
question = m.get("question", "")
price = float(m.get("outcomePrices", "[0.5]").strip("[]").split(",")[0])
est = estimate_probability(question, price)
if not est:
continue
ev = calculate_ev(est["estimated_probability"], price)
if ev["gap"] >= MIN_GAP and est.get("confidence") in ("HIGH", "MEDIUM"):
opportunities.append({
"question": question, "market_price": price,
"estimated": est["estimated_probability"],
"side": ev["side"], "ev": ev["ev"],
"confidence": est["confidence"],
"reasoning": est.get("reasoning", "")
})
opportunities.sort(key=lambda x: x["ev"], reverse=True)
for opp in opportunities:
print(f"{opp['side']} {opp['question'][:60]}...")
print(f" Market: {opp['market_price']:.0%} Claude: {opp['estimated']:.0%} EV: ${opp['ev']:.2f}")
return opportunitiesThis ties the pieces together into a single function you can call once or twice a day. It fetches contracts, runs Claude’s analysis on each one, filters by gap and confidence, and prints the ranked opportunities.
How do you track whether Claude is actually calibrated?
def update_calibration(question, estimate, resolved_yes):
"""Track Claude's probability calibration over time."""
try:
with open("calibration.json", "r") as f:
data = json.load(f)
except (FileNotFoundError, json.JSONDecodeError):
data = []
data.append({"question": question, "estimate": estimate,
"actual": 1 if resolved_yes else 0})
with open("calibration.json", "w") as f:
json.dump(data, f, indent=2)
def print_calibration():
"""Show calibration by probability bucket."""
with open("calibration.json", "r") as f:
data = json.load(f)
buckets = {}
for d in data:
bucket = round(d["estimate"], 1)
if bucket not in buckets:
buckets[bucket] = {"total": 0, "yes": 0}
buckets[bucket]["total"] += 1
buckets[bucket]["yes"] += d["actual"]
for b in sorted(buckets):
t, y = buckets[b]["total"], buckets[b]["yes"]
print(f" {b:.0%} bucket: {t} bets, {y/t:.0%} resolved YES")Run print_calibration() after 30+ resolved contracts. If the 60% bucket produces roughly 60% YES outcomes, Claude is well calibrated. If it consistently overestimates, widen your minimum gap threshold.
How do you measure if Claude is actually calibrated?
Two metrics:
- Brier score: Average of (predicted probability - actual outcome)^2 across all predictions. Lower is better. A score under 0.15 is good. Random guessing scores 0.25.
- Calibration buckets: Group predictions by confidence range (50-60%, 60-70%, etc.). In the 70% bucket, ~70% of predictions should resolve Yes. If 90% resolve Yes, Claude is underconfident. If 50% resolve Yes, Claude is overconfident.
Track both over at least 50 predictions before trusting the system with real money.
What should you actually do?
- If you are new to prediction markets: create a Polymarket account, run the bot, and place $10-$25 manual bets on HIGH confidence picks for one week. Track outcomes. Get the feel before automating.
- If you want to scale: run both Polymarket (political + crypto) and Kalshi (economic + financial) simultaneously. Different platforms, same analysis pipeline, more opportunities.
- If your calibration is off: widen the minimum gap from 10% to 15%. Accept fewer bets with higher conviction. Quality over quantity.
bottom_line
- Prediction markets are the widest AI edge in this book. Claude competes against headline-reactive retail bettors, not hedge fund quant teams.
- The expected value formula is the entire strategy:
EV = (estimated_prob * $1.00) - price. If EV is positive and the gap exceeds 10%, bet. - Track calibration religiously. A bot that disagrees with the market on everything is not smart. It is broken. The calibration tracker tells you which one you have.
Frequently Asked Questions
Does Polymarket AI trading actually work?+
Early testers report positive expected value from LLM-driven mispricing detection on Polymarket. Your results will depend on market conditions, model calibration, and signal threshold settings. Economic data contracts tend to produce the widest gaps.
How much money do I need to start trading on Polymarket?+
No minimum bet. You can start with $10-$50 per contract. A total wipeout across 10 diversified bets costs $100-$500. Compare that to a bad week in options trading.
What types of Polymarket contracts have the biggest AI edge?+
Economic data releases (CPI, jobs, GDP) produce 8-15 percentage point gaps between Claude's estimate and market price. Corporate earnings produce 5-10 point gaps. Political events vary wildly from 3-20 points.
More from this Book
How to Build an AI Stock Screener Bot with Python
Build a Python stock screener that uses Claude and Unusual Whales MCP to scan live options flow, score multi-signal convergence, and output a ranked watchlist.
from: Use Claude to Build an AI Trading Bot One Weekend
Kelly Criterion Position Sizing for Trading Bots
Implement Kelly Criterion in Python for automated position sizing with three worked examples, quarter-Kelly adjustments, and a copy-paste risk manager class.
from: Use Claude to Build an AI Trading Bot One Weekend
Monte Carlo Backtesting for Trading Strategies
Build a Monte Carlo backtesting framework in Python that runs 1,000 simulations, produces a fan chart, and tells you if your strategy has a real edge.
from: Use Claude to Build an AI Trading Bot One Weekend
How to Build a Multi-Agent AI Trading System
Build a 4-agent trading system in Python where Claude instances specialize as analyst, risk manager, executor, and monitor with adversarial disagreement.
from: Use Claude to Build an AI Trading Bot One Weekend