Agent Loop vs Single Prompt vs Fan-Out: When to Use Each
When to use an agent loop vs a single prompt vs fan-out comes down to task shape. A 3-question test routes any coding task to the cheapest tool that fits.
>This is the decision before the build. Claude Code Loop Engineering builds the bounded loop, the verification gate, and the budget cap once you've decided a task earns one.

Claude Code Loop Engineering
Build Self-Correcting Agentic Loops That Ship Trusted Code, Not a $200 Overnight Bill
Summary:
- Three shapes: one good prompt, a bounded loop, a fan-out. Most tasks are the first.
- A 3-question test routes any task: verifiable by command, repeats, parallelizes.
- The costliest mistake is looping a task that never needed one. The tax is invisible.
- Decision table plus the question that decides fan-out: does THIS task parallelize?
When to use an agent loop vs a single prompt is the judgment that saves the most money in agentic coding, and it comes before any build. You can spend chapters learning to build loops, gates, and adversarial reviewers, and the single most expensive mistake is still not the runaway loop. It’s the loop you built for a task that never needed one. A runaway burns money once and teaches you a lesson. An unnecessary loop burns money quietly, forever, every time it runs.
When should you build a loop vs just ask once?
Start from the null hypothesis: this task does not need a loop, and the work has to prove it does. Most coding tasks are one good model call. Edit this file. Write this function. Fix this specific error. There’s no condition to converge against, so wrapping it in a loop makes it slower and more expensive for a byte-identical result.
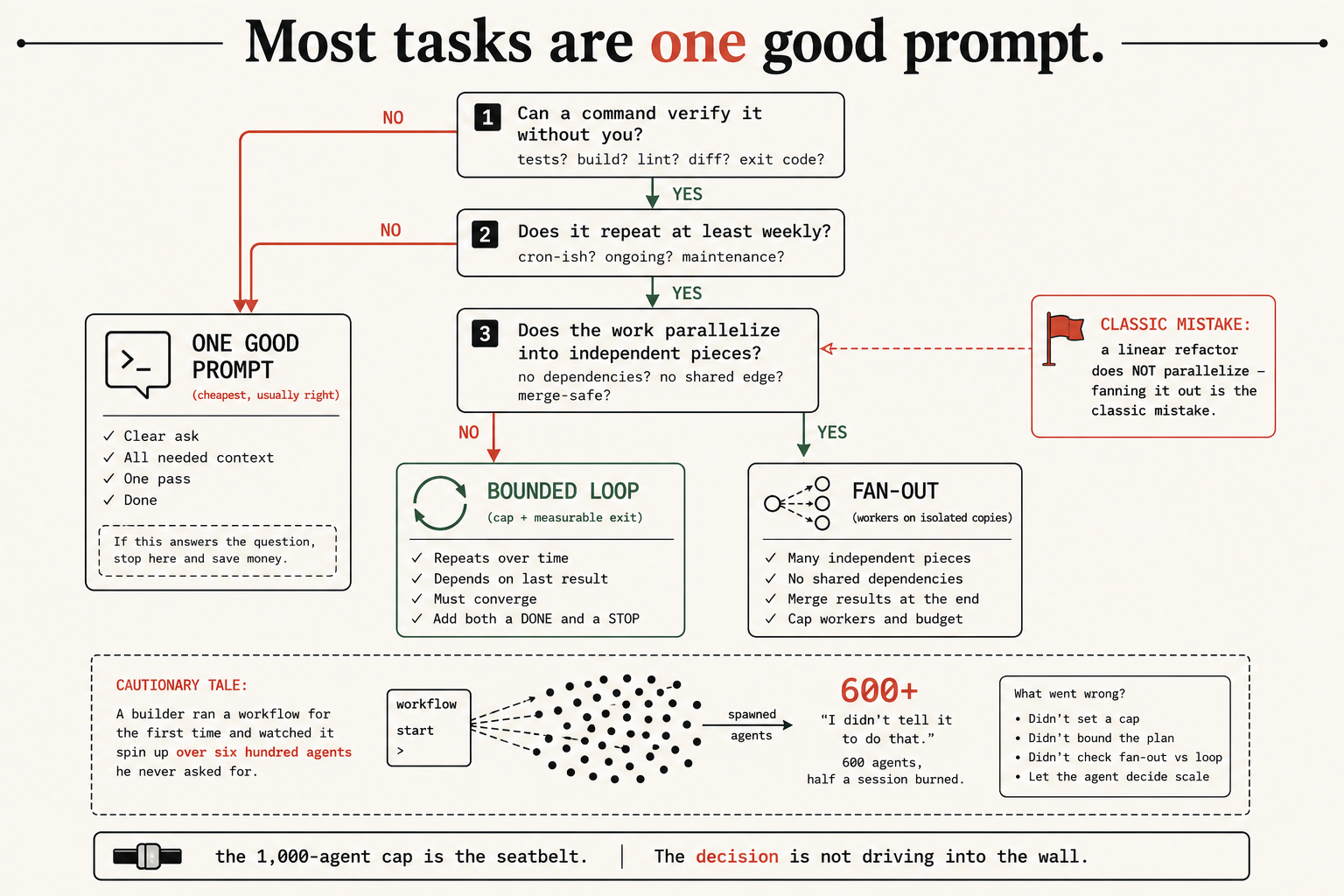
A short decision tree sorts any task into the right shape. Three questions, in order:
1. Can a command verify it without you? (tests? build? lint? diff? exit code?)
2. Does it repeat at least weekly? (cron-ish? ongoing? maintenance?)
3. Does the work parallelize into independent pieces? (no dependencies? merge-safe?)Walk them and you land on one of three outcomes:
| Shape | When | The cost trap |
|---|---|---|
| One good prompt | No gate, or a one-off. Cheapest, usually right. | none; this is the correct default |
| Bounded loop | A command verifies it AND it repeats. Cap + measurable exit. | over-looping a one-off |
| Fan-out | The work splits into independent pieces. Workers on isolated copies. | fanning out a linear refactor |
The first question is the big one. If nothing but your own eyeballs can judge “done,” you don’t have a loop, you have a thing you have to babysit, which is the opposite of the point. A loop earns its existence only when a test, a build, or a linter can fail the work while you’re not in the room.
For the green-lit loops, a thirty-second gut check before each run keeps them safe to walk away from:
THE 30-SECOND LOOP CHECK (run before every task):
1. The task happens at least weekly. (less: setup never amortizes)
2. A test/typecheck/build/linter can reject bad output. (none: it grades its own homework)
3. The agent can run the code it changes. (no repro env: iteration is blind)
4. There's a hard stop: budget, iteration count, time. (none: runs until the bill)
5. A human reviews before merge/deploy/dependency change. (irreversible: approval gate)A loop that passes the test still gets launched bounded, with both brakes nailed shut before it starts:
$ claude -p "/goal the failing test in test/auth passes (npm test exits 0) or stop after 8 turns" \
--max-budget-usd 3The turn clause caps how long it churns. The dollar flag caps what it can spend. That’s a loop you can start and walk away from.
When should you fan out instead?
Fan out only when the work splits into independent pieces that run at the same time without stepping on each other. The debate online is usually framed as “isn’t fan-out 15x the cost,” and that’s the wrong question. The right one, as one builder sharpened it, is whether the task fits:
“it only becomes waste when hundreds of subagents fire on a task that does not parallelize, like a single-file edit or a linear refactor. so the real question is not is 15x too much, it is does THIS task fan out.”
(u/tonyboi76, 117 upvotes, in the r/ClaudeCode thread on multi-agent token cost.)
Cost is downstream of fit. A codebase-wide audit, check every endpoint for a missing auth check, parallelizes: forty endpoints, forty independent questions, forty agents with no coordination. A linear refactor does not. Each step depends on the one before it, so forty agents trip over each other and you’ve spent the multiplier for nothing. Here are the two cases side by side:
TASK A: audit every route under src/routes/ for a missing auth check.
-> Independent per-file work that PARALLELIZES. VERDICT: fan out.
TASK B: a linear refactor where step 2 depends on step 1's output.
-> Does NOT parallelize. VERDICT: do not fan out; it buys nothing on sequential work.A linear refactor landing on fan-out is the classic mistake. The test is mechanical: independent pieces, fan out; dependent chain, don’t.
What does over-looping actually cost?
It costs a quiet tax forever, and invisible costs are the ones that bleed you. Take a routine single-file edit. As one prompt, it costs pennies and a few seconds. Wrap it in a loop with a verification gate and it re-runs the suite, re-reads the output, re-checks the condition, maybe takes an exploratory turn or two, and costs several times more for the same result:
SAME TASK: "rename a function in one file and update its caller":
As one prompt: 1 turn. Reads the file, makes the edit, returns. Pennies, seconds.
Wrapped in a loop:
turn 1 edit the file
turn 2 run the full test suite (nothing it changed is tested here)
turn 3 re-read the output, re-check condition
turn 4 exploratory "is there anything else?" pass
-> same result, several times the cost, every single run.Nothing breaks. No horror story gets posted. It just costs a multiple of what it should, every time it runs, and it feels sophisticated the whole way, which is the trap. A team that reflexively loops everything is paying that multiple across its entire routine workload and calling it “going agentic.” Right shape, right cost. Wrong shape and you pay, either in money you didn’t notice or time you can’t get back.
The 600-agent cautionary tale
Here’s what happens when nobody makes the decision and the tool makes it for you. A builder ran a workflow for the first time and watched it spin up over six hundred agents he never asked for. His words: “I didn’t tell it to do that.” It burned through more than half his session and a chunk of his weekly quota in a single call. He wasn’t reckless. He handed a big fuzzy task to a fan-out tool without deciding whether it wanted six agents or six hundred, and the tool, eager to help, chose six hundred.
There’s a 1,000-agent cap built in precisely to stop this from going truly infinite, and thank goodness for it. But a cap that saves you from infinity still lets you burn a weekend’s budget in a minute. The cap is the seatbelt. The decision is not driving into the wall in the first place.
What should you actually do?
- If a command can’t verify it → single prompt. No automated gate means no loop, just a careful prompt with you in the room.
- If it’s a one-off → single prompt, even if a gate exists. The loop’s setup cost never amortizes on a task you run once.
- If it repeats and a test can fail it → bounded loop, launched with a turn cap and
--max-budget-usd. - If it splits into independent same-shaped pieces → fan out, and cap the workers. If it’s a dependent chain, don’t; you’ll pay the multiplier for nothing.
The bottom line
- Most things people ship as “agents” should be a workflow with one model call. That’s not anti-loop cynicism, it’s the restraint a senior engineer brings to any power tool.
- The shape decision isn’t bureaucracy before the real work. It is the real work. The framework you pick barely matters; the judgment about which shape a task needs is tool-agnostic and it’s the whole skill.
- Decide the shape before you spend a token. Fan-out is the most expensive shape to get wrong, and the tool will happily choose six hundred agents if you don’t choose first.
Frequently Asked Questions
When should I use an agent loop instead of a single prompt?+
Only when the task repeats, a command can verify it without you, your budget can absorb the waste, and the agent has real tools. Miss any one of those and a single good prompt almost always wins. Most coding tasks are one prompt.
When does fanning out to many agents actually help?+
Only when the work splits into independent pieces that run at the same time without colliding, like auditing 40 separate files. A linear refactor where step 2 depends on step 1 does not parallelize, so fan-out buys nothing.
What's the most expensive mistake in agentic coding?+
It isn't the runaway loop. It's the loop you built for a task that never needed one. It burns several times the cost of a single prompt, quietly, every time it runs, and feels productive the whole way.