Build a Multi-Model AI Council with OpenRouter
Route one question to GPT, Claude, Gemini, and Grok through OpenRouter so no single vendor's blind spot decides your answer. The multi-model council build.
>This is the routing layer. The LLM Council uses it under the code-review board and the fact-gate, where one family's blind spot is most expensive.

The LLM Council
Stop Your Yes-Man AI and Build a Board of Advisors That Argues Before It Agrees
Summary:
- Build a council whose advisors run on four different model families, not four personas of one model.
- OpenRouter routes GPT, Claude, Gemini, and Grok through one endpoint and one key.
- Different lineages have different blind spots, so genuine disagreement becomes real signal.
- Bonus: the live model slugs, the jq-safe call pattern, and the separate Ollama route for a local advisor.
A multi-model AI council routes one question to four different model families through OpenRouter, so no single vendor’s blind spot decides your answer. Five personas of one model still share that one model’s training and its center of gravity. When you need real independence, you need real different models in the room.
How do you build a multi-model AI council?
You point each advisor at a different model family and call it through OpenRouter’s single endpoint. OpenRouter is a routing layer that speaks to many model families through one OpenAI-compatible endpoint, billed through one key. You send one request shape, name the model in the body, and OpenRouter forwards it to the right provider.
The endpoint and auth are short, and worth getting exactly right:
Endpoint: https://openrouter.ai/api/v1/chat/completions
Header: Authorization: Bearer $OPENROUTER_API_KEYOne trap: do not hand-assemble the JSON. The moment a decision contains a quote or a newline it corrupts the request and you blame OpenRouter. Build the body with jq, which escapes anything, and pull the reply with jq too:
jq -n --arg model "openai/gpt-5.1" --arg content "$PROMPT" \
'{model: $model, messages: [{role: "user", content: $content}]}' \
| curl -s https://openrouter.ai/api/v1/chat/completions \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d @- \
| jq -r '.choices[0].message.content'That is one advisor running on GPT. Change the model field and the persona, and you have a different advisor on a different family.
Why not just five personas of one model?
Because five personas of one model share one model’s blind spots. The word for it is correlated error: if every advisor learned from the same data, their mistakes line up, and five agreeing answers look like proof when they are really one echo with a quorum. Personas change a model’s stance, not its knowledge. Tell Claude to be a harsh skeptic and you get a harsh skeptic with exactly Claude’s gaps.
Genuine independence needs genuinely different models. When GPT, Claude, and Gemini disagree, that split is real, because different teams trained them on different data with different choices baked in. Where they converge, three independent systems agreed. Where they diverge, you found the exact spot that deserves a second look.
Which models go in the room?
You assign each advisor a family so the room spans vendors, not just personas. All four families are reachable through that one OpenRouter endpoint right now, confirmed live from the public models API (GET https://openrouter.ai/api/v1/models):
| Model family | OpenRouter id | Context length |
|---|---|---|
| OpenAI GPT-5.1 | openai/gpt-5.1 | 400,000 |
| Google Gemini 3.1 Pro Preview | google/gemini-3.1-pro-preview | 1,048,576 |
| Anthropic Claude Sonnet 4.5 | anthropic/claude-sonnet-4.5 | 1,000,000 |
| xAI Grok 4.3 | x-ai/grok-4.3 | 1,000,000 |
Pin plain provider/model slugs like these for reproducible councils. (A note that saves an afternoon: Karpathy’s original repo still pins the older google/gemini-3-pro-preview and x-ai/grok-4, which have since rolled forward on OpenRouter’s live catalog. Slugs drift. Copy the exact id from openrouter.ai/models, never from memory.)
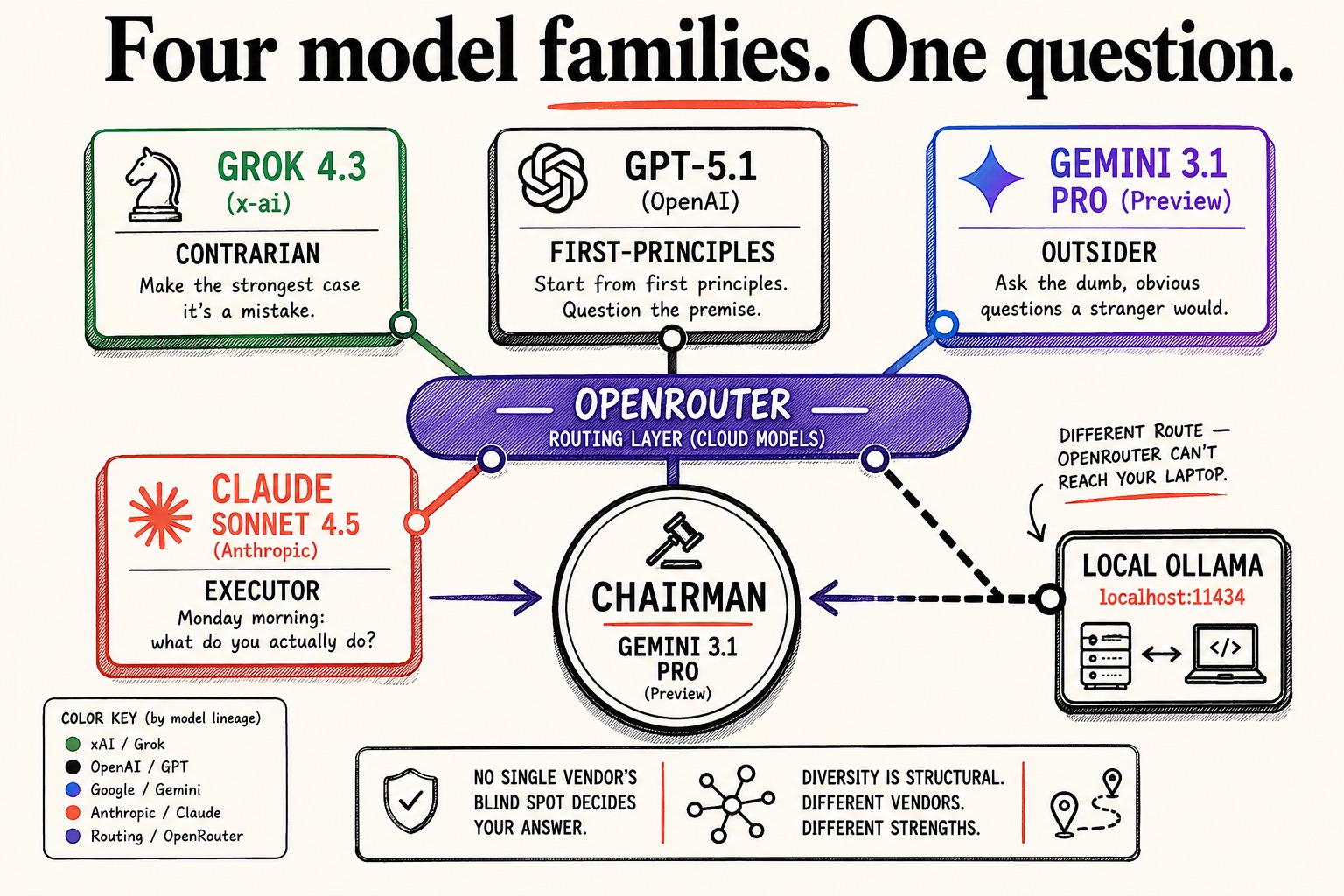
Now add the routing to your SKILL.md. Assign families, then call each through OpenRouter, and send the chairman to one consistent model:
MULTI-MODEL ROUTING. Assign each advisor a family, call it through OpenRouter
with the jq pattern above, and capture each reply as that advisor's answer:
contrarian -> x-ai/grok-4.3
first-principles -> openai/gpt-5.1
outsider -> google/gemini-3.1-pro-preview
executor -> anthropic/claude-sonnet-4.5
Run peer review and chairman as before. Route the chairman to one model
(default: google/gemini-3.1-pro-preview). Log which model produced which answer.The four-stage spine is unchanged. The only difference is that box two now fans out across four lineages. Your Contrarian is Grok, your First-Principles advisor is GPT, your Outsider is Gemini, your Executor is Claude, and the chairman that synthesizes them is Gemini. When they disagree now, four different AI lineages are disagreeing.
Watch the families disagree
The payoff is concrete. Run a technical decision through the four-family council, “should we use a message queue or just a database table for our background jobs,” and the families often split along lines that map to their training.
One reaches for the message queue as the obvious professional choice. Another pushes back: a database table you already run is simpler, with no new infrastructure to operate, and you can migrate later when scale actually demands it. A third asks the volume question nobody answered, because the right answer flips at different scales. The fourth flags an operational cost the others skipped: a queue is one more thing to monitor and get paged about at 3 a.m.
A single model would have confidently recommended one option, and which one you got would have been an accident of which family you happened to ask. The council surfaced that the answer is scale-dependent, which is the actual truth. The chairman comes back not with “use a queue” but with “below a few hundred jobs a minute, use the table you already have; above that, the queue earns its complexity, so measure your volume first.” That reframing is worth more than any single answer, and you only got it because the room held more than one kind of mind.
What broke when I wired it up
Multi-model adds failure modes the single-model council never had. The ones you will actually hit:
- Every advisor returns an auth error. Your
OPENROUTER_API_KEYis not set in the skill’s environment, or it expired. Test it with one bare curl before debugging five layers of skill logic. - One model errors with “model not found.” A bad slug. You typed
openai/gpt5.1instead ofopenai/gpt-5.1. A wrong slug does not degrade gracefully, it just fails. Copy the exact id from the models page. - You cannot tell which model said what. You forgot the attribution. Record the model slug next to every answer in the log, or the disagreements teach you nothing.
- Answers change run to run. You used a tilde always-latest alias and the underlying model rolled under you. Pin the plain slugs and save the surprise for the decisions, not the infrastructure.
Add a local model with Ollama
Maybe you want a voice in the room that owes nothing to any cloud vendor. You can, but read this twice: a local Ollama model is a separate route from OpenRouter. OpenRouter is cloud and cannot reach a model on your laptop. So your council ends up with two transports: cloud advisors through OpenRouter, and a local advisor through Ollama’s own endpoint.
Pull a model, and it serves an OpenAI-compatible endpoint at localhost:11434:
ollama pull llama3.1
jq -n --arg content "You are the OUTSIDER advisor. DECISION: $DECISION" \
'{model: "llama3.1", messages: [{role: "user", content: $content}]}' \
| curl -s http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d @- \
| jq -r '.choices[0].message.content'Same jq body, pointed at localhost, no auth header because it is your machine. If the local advisor returns confused answers on a long prompt, suspect its context limit before the model. A local model’s context is tied to your hardware, not a fixed default.
What should you actually do?
- If the decision is about judgment (“is this plan sound”) → a single-family council of five personas is plenty, and cheaper. Persona diversity already breaks sycophancy.
- If the decision is about knowledge or correctness (“is this architecture right”) → go multi-model, because one family’s training gap is exactly what sinks you.
- If you want a private voice → add the Ollama route, and remember it is a separate transport from OpenRouter.
- If results jump around → pin exact slugs and log the model on every answer.
The bottom line
- Persona diversity fights sycophancy; model diversity fights bias and blind spots. Pick the council that matches the failure you actually fear.
- One endpoint, one key, four lineages. OpenRouter is the cheapest way to get genuine model diversity into one command.
- The disagreement is the product. Four families splitting on your question is the signal a single confident answer would have hidden.
Frequently Asked Questions
What is a multi-model AI council?+
A multi-model AI council sends the same question to different model families (like GPT, Claude, Gemini, and Grok) instead of one model wearing several hats. Different lineages have different blind spots, so where they agree you trust it more and where they split you look harder.
Can OpenRouter route to a local Ollama model?+
No. OpenRouter is a cloud service that reaches cloud providers only. A local Ollama model is a separate route to your own machine at localhost:11434. A working OpenRouter key does nothing for the local model.
Do I need separate API keys for GPT, Claude, and Gemini?+
No. OpenRouter speaks to many families through one endpoint and one key. You name the model in the request body and OpenRouter forwards it to the right provider, so you wire one integration, not three.