How to Build a Contrarian Bot for Polymarket
A Polymarket contrarian bot that uses base rates, engagement-weighted sentiment, and a political-market insider filter. With Python code and examples.
>This builds the detection logic. Polymarket Profits 2 wires the contrarian bot into a 7-strategy portfolio with correlation-aware allocation and a paper-trading rig.

Summary:
- A contrarian bot buys the opposite side when the crowd overshoots fair value.
- Fair value comes from historical base rates, not from the current price.
- Engagement-weighted sentiment scoring catches viral overreactions that drive mispricing.
- A market-type filter keeps the bot out of political markets where insiders own the crowd.
I put $400 on the wrong side of a crowd. Political policy announcement, YES at $0.83, Twitter at 92% bullish, fair value estimate at $0.70 from historical policy-announcement base rates. Textbook contrarian setup. Bought NO at $0.17, waited for the crowd to be wrong, and the crowd was right. NO shares went to $0.00. The $400 was gone.
That trade taught me the filter the first version was missing. Political markets attract both retail hype and insiders, and my bot could not tell them apart. This article is the contrarian bot that works: fair value from base rates, engagement-weighted sentiment, and a hard rule to skip the markets where insiders drive the price.
What is a contrarian bot?
Contrarian bot is a trading bot that detects when crowd sentiment has pushed a Polymarket price past the historical base rate for that event type, then buys the opposite side. The edge is the gap between what people feel and what actually happens across a large sample of similar events.
Example. A celebrity tweets they are “considering” running for office. Twitter goes wild. “Will [Celebrity] file to run?” jumps from $0.15 to $0.55 in four hours as fans pile into YES. But the historical base rate for celebrities who “consider” running and actually file is about 12%. Your bot reads the sentiment spike (88% bullish), compares to the base rate (12%), and finds a 43-cent edge. It buys NO at $0.45. Over the next week, excitement fades, no filing happens, the price drifts back to $0.20. You sell NO at $0.80.
That trade sat there for hours because emotional traders do not check base rates. They buy what they want to be true. The contrarian bot sells what the data says is true.
How do you measure fair value on a prediction market?
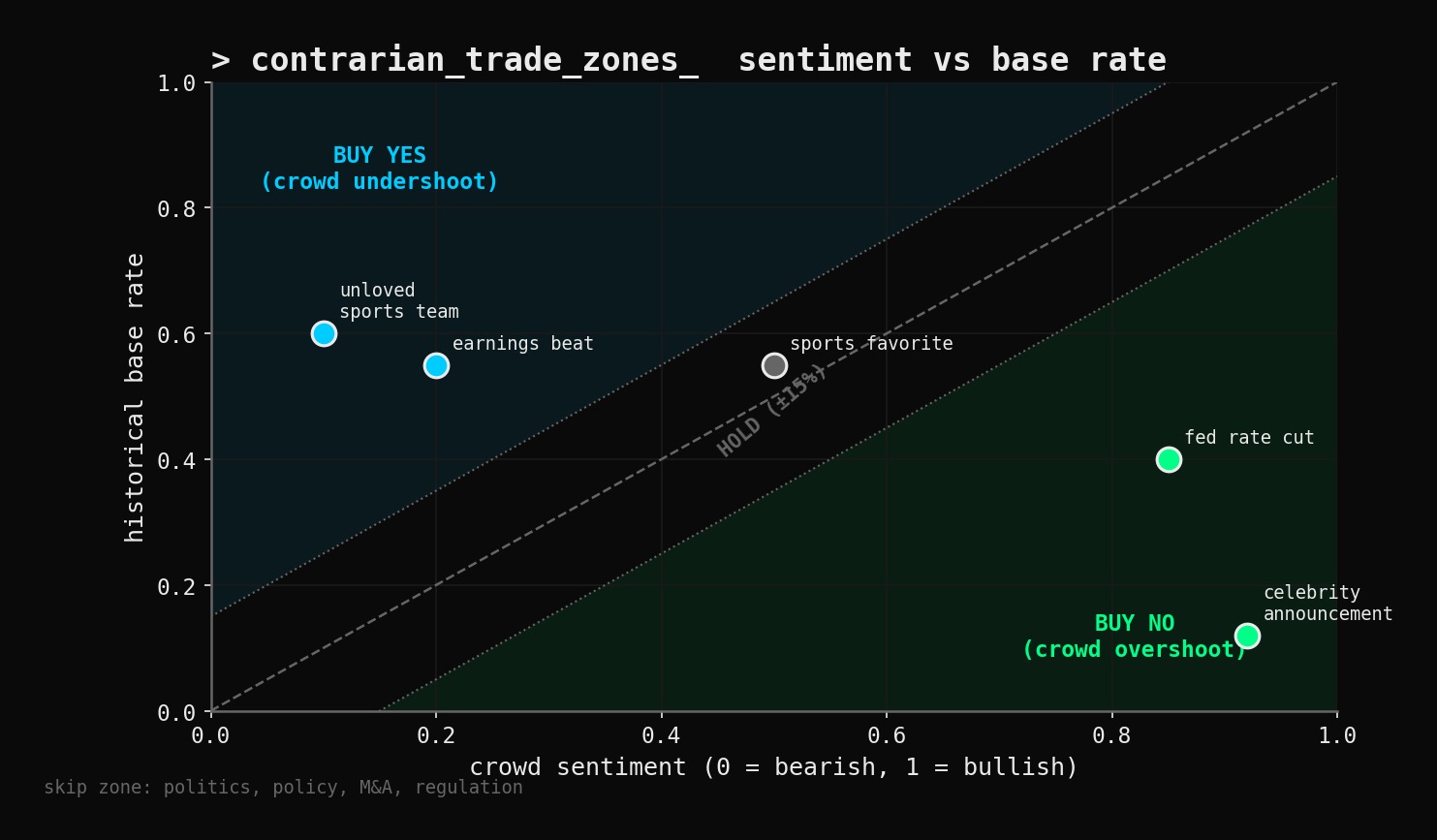
You measure it by classifying the market type and looking up the historical base rate for that type. Not by reading the current price. Current price is what the crowd thinks. Base rate is what actually happens across hundreds of similar events.
class FairValueEstimator:
def __init__(self):
self.base_rates = {
"celebrity_announcement": 0.12,
"policy_announcement": 0.70,
"earnings_beat": 0.55,
"fed_rate_cut": 0.40,
"sports_favorite_wins": 0.60,
"crypto_round_number": 0.50,
}
def estimate(self, market_type, current_price):
base = self.base_rates.get(market_type, 0.50)
edge = current_price - base
return {
"base_rate": base,
"current_price": current_price,
"overvaluation": edge,
"contrarian_edge": edge if abs(edge) > 0.05 else 0,
"direction": (
"BUY_NO"
if edge > 0.05
else "BUY_YES"
if edge < -0.05
else "HOLD"
),
}These base rates are starting defaults. Build better ones from actual resolved Polymarket markets. Here is the loop:
import requests
from collections import defaultdict
GAMMA_BASE = "https://gamma-api.polymarket.com"
def build_base_rates(category_classifier):
"""Compute YES resolution rates from resolved Polymarket markets.
category_classifier A function that takes a market dict and
returns a category string (your own rules).
Returns a dict: {category: (yes_rate, sample_count)}.
"""
resp = requests.get(
f"{GAMMA_BASE}/markets",
params={"closed": "true", "limit": 500},
timeout=10,
)
resp.raise_for_status()
markets = resp.json()
counts = defaultdict(lambda: {"yes": 0, "total": 0})
for m in markets:
category = category_classifier(m)
if not category:
continue
outcome = m.get("outcomePrices") or []
# Resolved markets have a final outcome price of 1.0 on the winning side
if not outcome:
continue
yes_won = float(outcome[0]) > 0.5
counts[category]["total"] += 1
if yes_won:
counts[category]["yes"] += 1
return {
cat: (c["yes"] / c["total"], c["total"])
for cat, c in counts.items()
if c["total"] >= 20 # Drop thin samples
}Run it once a week with your own category_classifier. After a month of resolved data, your estimates get much tighter than the hardcoded numbers. A 20-sample floor keeps thin categories out of the table so you do not size trades on 3 data points.
How do you score sentiment without getting fooled by bots?
You weight every tweet by engagement (likes + retweets + 1). A viral tweet with 5,000 likes saying “this is guaranteed” counts 5,000 times more than 50 spam accounts saying the same thing. Engagement-weighted sentiment matches reality because viral posts drive crowd behavior, not bot networks.
def sentiment_score(tweets, min_tweets=20):
"""Score social sentiment from 0 (all bearish) to 1 (all bullish).
Each tweet is weighted by engagement (likes + retweets + 1).
Returns 0.50 if fewer than min_tweets scored tweets are found.
"""
bull = [
"bullish", "yes", "guaranteed", "100%", "done deal",
"lock", "certain", "printing", "moon", "lfg",
]
bear = [
"bearish", "no", "impossible", "never", "no chance",
"overvalued", "dump", "rekt", "zero", "not happening",
]
bullish_weight = 0
bearish_weight = 0
scored = 0
for tweet in tweets:
text = tweet.get("text", "").lower()
metrics = tweet.get("public_metrics", {})
weight = (
metrics.get("like_count", 0)
+ metrics.get("retweet_count", 0)
+ 1
)
is_bull = any(w in text for w in bull)
is_bear = any(w in text for w in bear)
if is_bull and not is_bear:
bullish_weight += weight
scored += 1
elif is_bear and not is_bull:
bearish_weight += weight
scored += 1
if scored < min_tweets:
return 0.50 # Not enough data
total = bullish_weight + bearish_weight
return bullish_weight / total if total else 0.50When the score exceeds 0.85 (85%+ weighted bullish), the market is in overreaction territory. Below 0.15 is the same thing in reverse. Between 0.30 and 0.70, the crowd is split and there is no contrarian signal.
The min_tweets=20 floor prevents the bot from trading thin data. If only 8 people tweeted about a topic, you do not know what the crowd thinks.
Known failure modes of keyword sentiment. This function is a starting point, not a production NLP pipeline. It will fail on:
- Sarcasm: “oh yeah, this is definitely happening 🙄” counts as bullish.
- Negation: “not bullish” matches both
"bullish"and"not", so the function treats it as bullish. - Coordinated campaigns: engagement weighting helps, but a viral meme template can still swing the score if hundreds of accounts copy it.
- Topic drift: the keyword “moon” trades differently in crypto markets vs sports markets.
Before going live, run the function against 200 labeled tweets from your target category and measure precision/recall. If either drops below 70%, replace the keyword lists with a small fine-tuned classifier or a zero-shot LLM call. For sports and entertainment markets, the naive version is usually good enough. For anything political, it is not.
What broke when my first version traded politics?
The $400 political trade broke because my scanner could not distinguish “92% bullish is retail hype” from “92% bullish is people who know the answer.” After that loss I stopped trusting sentiment on political markets, policy announcements, mergers, and regulatory decisions. Not because I could prove insider flow exists on every one of them, but because my sentiment score could not tell the difference and the losses were bigger than the wins.
Here is what the top active markets look like on Polymarket right now, pulled live from gamma-api.polymarket.com/events:
| Market | Category | 30-day Volume | Contrarian filter |
|---|---|---|---|
| Starmer out in 2025 | Politics | $6.98M | SKIP |
| Macron out in 2025 | Politics | $0.46M | SKIP |
| Curaçao win 2026 FIFA World Cup? | Sports | $16.63M | TRADE |
| South Korea win 2026 FIFA World Cup? | Sports | $8.43M | TRADE |
| Algeria win 2026 FIFA World Cup? | Sports | $8.35M | TRADE |
| New Zealand win 2026 FIFA World Cup? | Sports | $7.76M | TRADE |
| Spain win 2026 FIFA World Cup? | Sports | $7.39M | TRADE |
The political markets get skipped by the filter. I do not trust sentiment on anything where a single leak or campaign signal can move the price before retail sees it. The sports markets are fair game because the outcome is driven by on-field performance that is equally visible to every trader. Sentiment spikes on a team after a single viral highlight are the exact kind of overreaction a contrarian bot is built to catch.
The fix is a 10-line filter you call before every trade:
AVOIDED_CATEGORIES = {
"politics",
"policy_announcement",
"regulation",
"merger",
"acquisition",
"legal_ruling",
"central_bank_policy",
}
def should_trade_contrarian(market_category):
"""Return False if the market is in an insider-heavy category."""
return market_category.lower() not in AVOIDED_CATEGORIESRun this before every potential contrarian trade. Zero political or policy positions since I added it. Zero losses like the $400 one.
How do you put the pieces together into a working bot?
You chain the four pieces into a single decision loop: classify the market, compute fair value, score sentiment, apply the category filter, then decide.
def contrarian_decision(market, tweets, current_price):
"""Decide whether to take a contrarian position on a market.
Returns ("BUY_YES" | "BUY_NO" | "HOLD", reasoning dict).
"""
# Step 1: Classify and filter
category = classify_market_type(market) # Your classifier
if not should_trade_contrarian(category):
return "HOLD", {"reason": f"skipped: {category}"}
# Step 2: Fair value from base rates
estimator = FairValueEstimator()
fv = estimator.estimate(category, current_price)
if fv["contrarian_edge"] == 0:
return "HOLD", {"reason": "edge too small"}
# Step 3: Confirm with sentiment
sent = sentiment_score(tweets)
crowd_bullish = sent > 0.85
crowd_bearish = sent < 0.15
# Step 4: Decide
if fv["direction"] == "BUY_NO" and crowd_bullish:
return "BUY_NO", {
"base_rate": fv["base_rate"],
"current_price": current_price,
"sentiment": sent,
"edge": fv["contrarian_edge"],
}
if fv["direction"] == "BUY_YES" and crowd_bearish:
return "BUY_YES", {
"base_rate": fv["base_rate"],
"current_price": current_price,
"sentiment": sent,
"edge": -fv["contrarian_edge"],
}
return "HOLD", {"reason": "no sentiment confirmation"}The key rule: base rates identify the edge, sentiment confirms the overreaction, and the category filter protects you from markets where sentiment is wrong about what is wrong. All three must agree before the bot trades.
Plug the contrarian decision loop into the paper-trading trainer from Chapter 3 of Polymarket Profits 2. Contrarian trades are infrequent (1-5 per day) and the edge only shows up across 50+ trades, so the trainer is where you validate that the fair-value + sentiment + category filter actually converges to profit before any real USDC is on the line.
Related in this series
- Polymarket Trading Fees: The Real Formula. The fee math that eats thin contrarian edges.
- Polymarket Position Sizing With Fee-Adjusted Kelly. Quarter-Kelly for the binary payouts contrarian bets produce.
- How to Build a Polymarket Resolution Scanner. A complementary strategy with different timing.
- How to Detect Edge Decay in Your Trading Bot. Contrarian edges decay the slowest, but still decay.
What should you actually do?
- Build base rates from real Polymarket data. Pull 30 days of resolved markets, classify by type, calculate the YES resolution rate per category. Update weekly as new markets resolve.
- Start with entertainment, sports (not championships), and minor celebrity markets. These are sentiment-driven with low insider flow. Perfect contrarian territory.
- Require all three signals before trading. Edge from base rates, confirmation from sentiment (> 0.85 or < 0.15), category in the approved list. Two out of three is not enough.
- Paper trade for 30 days minimum. Contrarian strategies have long quiet stretches then burst into activity. You need a full cycle to know the win rate.
- Never trade politics, policy, mergers, or regulatory announcements. No exceptions. The $400 I lost is what “one exception” costs.
bottom_line
- The crowd is usually right. Contrarian trading only works when you can prove the crowd is reacting to emotion instead of data.
- Base rates and sentiment must agree. Either one alone gives you false signals.
- The market-type filter is the most important line of code in the whole bot. Skip the filter, lose the account.
Frequently Asked Questions
What is a contrarian bot on Polymarket?+
A contrarian bot detects when crowd sentiment overshoots fair value on a Polymarket market and takes the opposite side. It uses historical base rates plus engagement-weighted social sentiment to find gaps between what people believe and what the data actually supports.
Does contrarian trading work on Polymarket?+
Yes, on sentiment-driven markets (entertainment, sports, minor celebrity events) where crowd emotion drives the price. It fails on insider-information markets (politics, policy, mergers) where high confidence means people actually know the answer.
How do I know when the crowd is wrong vs when insiders are right?+
Apply a market-type filter. Skip politics, policy announcements, regulation, and M&A markets because insider flow dominates. Trade sports, entertainment, and minor-celebrity markets where sentiment is the main price driver.