How to Sandbox an AI Agent
How to sandbox an AI agent with four real walls: a default-deny egress allowlist, gVisor isolation, a read-only filesystem, and an approval gate you verify.
>This builds the box. AI Agent Security stacks it with scoped credentials, an input gate, and a pen-test suite that proves the walls hold.
AI Agent Security: Lock Down Claude Code, MCP Servers & OpenClaw
Stop Prompt Injection, Scope Your Credentials, and Ship Agents That Can't Be Owned
Summary:
- The four walls of a real agent sandbox, and which one matters most.
- A default-deny egress allowlist in Squid plus iptables, copy-paste ready.
- How to wrap the agent in gVisor with one Docker flag.
- The three by-hand tests that prove your box actually holds before you trust it.
Knowing how to sandbox an AI agent comes down to one idea: assume the injection succeeds, and arrange things so success doesn’t reach anything that matters. Permissions and credentials lower the chance of compromise. The sandbox lowers the blast radius of a compromise that already happened. It’s the layer that holds when everything upstream of it fails, because unlike a guardrail it doesn’t try to recognize the attack. It just states a fact about the environment: this process may write here and nowhere else, may reach these two hosts and no others. That fact holds for attacks nobody has invented yet.
Here’s how to build the box with four walls, and how to prove each one before you trust it.
How do you sandbox an AI agent?
You put it behind four walls: an isolation runtime, a read-only filesystem with one writable directory, a default-deny network egress allowlist, and an approval gate for destructive actions. The agent runs its real task inside all four, and a fully-hijacked agent still ends up in a room with no exits.
Picture the payoff before the setup. The agent has been fed a hostile email, the injection worked, and the model is convinced it should phone home to an attacker’s server at some unknown IP like 203.0.113.66 and exfiltrate a file. It opens the connection. The request hangs, then dies: connection refused. The injection fully succeeded. The only reason your data is still yours is that the packet had nowhere to go. That dead connection is the sound of the sandbox doing its job.
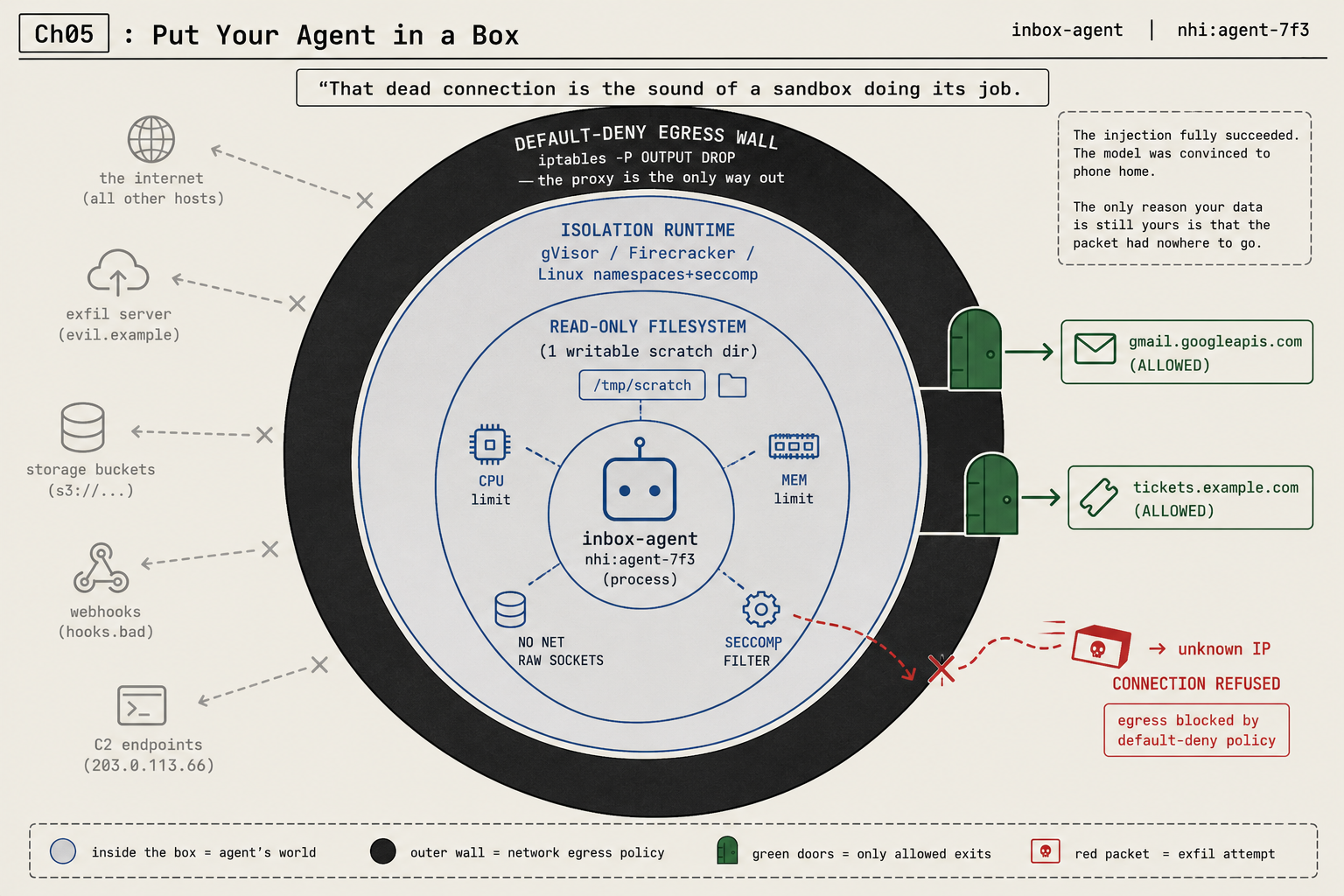
The egress allowlist is the wall that matters most
If you build only one wall, build this one. Almost every attack that actually hurts you needs the network at some point: exfiltration has to send your data somewhere, a command-and-control payload has to phone home, a stolen token has to be carried out. Cut outbound down to a short allowlist of the destinations the task genuinely needs, deny everything else, and you break most of these attacks even when every other layer has failed.
Route all the agent’s outbound traffic through a forward proxy that only permits the task’s domains. A few lines of Squid does it:
# /etc/squid/squid.conf: a default-deny egress allowlist for the agent.
acl agent_allow dstdomain gmail.googleapis.com tickets.example.com
http_access allow agent_allow
http_access deny all # anything not on the allowlist is refused (incl. HTTPS CONNECT)A proxy alone is a wall with a door cut next to it, because nothing yet stops the agent from opening a direct socket that ignores the proxy. So pair it with a kernel-level default-deny on the agent’s network namespace, so the single permitted route is to the proxy:
# On the agent's container/network namespace: drop all outbound, allow only the proxy.
iptables -P OUTPUT DROP # default: nothing leaves
iptables -A OUTPUT -o lo -j ACCEPT # loopback is fine
iptables -A OUTPUT -p tcp -d <proxy-host> --dport 3128 -j ACCEPT # only path out = the proxyPoint the agent at the proxy with HTTPS_PROXY=http://proxy-host:3128 and now there’s exactly one exit, the proxy, and it’s deny-by-default. An exfiltration attempt to evil.example, an s3:// bucket, or an unknown IP is refused twice: once by the firewall (anything that isn’t the proxy) and again by the proxy (anything not on the allowlist). The allowed green doors are gmail.googleapis.com and tickets.example.com, and nothing else.
One rule makes or breaks this: these rules must be installed by the host or the orchestrator, never by the agent process. Don’t give the agent CAP_NET_ADMIN or privileged container mode. If the compromised agent can edit the wall, the wall is decoration, exactly the way a permission rule the model can rewrite is no rule at all.
What broke: the injection that succeeded and still failed
The reason I trust the box more than any classifier is a sobering finding from a developer who red-teamed their own setup: the architectural protections, the sandboxing and permission scopes and tool allowlisting, “stopped zero attempts at every tier.” Zero. That sounds like an argument against sandboxing. It’s an argument against trusting a sandbox you never tested. A misconfigured box, a network rule with a typo, an egress allowlist that accidentally allows everything, feels like protection and provides none.
So the box is non-negotiable and so is attacking it. A sandbox you configured once and assumed was working is exactly as dangerous as a model you assume will refuse: it hands you confidence you didn’t earn. Build the box, then prove it holds, every time you change the agent’s environment.
Pick an isolation runtime
The single biggest tell of a shallow guide is that it says “run it in a sandbox” and never names one. There are real, named technologies here.
gVisor is an application kernel: a program that sits between your agent’s container and the host kernel, intercepting system calls so a single kernel bug isn’t a full escape. It’s the lowest-friction path, and it plugs straight into Docker. Register the runtime, then launch the container under it:
# Install the gVisor "runsc" runtime into Docker's config, then reload the daemon
sudo runsc install
sudo systemctl restart docker
# Run the agent's container inside the gVisor sandbox
docker run --runtime=runsc --rm <agent-image>That --runtime=runsc flag is verbatim from gVisor’s own Docker quick start (it needs Docker 17.09 or greater). That one flag is a dramatic reduction in what a container escape can reach.
Firecracker gives each workload its own tiny microVM with a genuine virtualization boundary, stronger than a container namespace. AWS built it, and it’s what runs Lambda and Fargate under the hood, millions of times a day. Reach for it when the code is something you genuinely don’t trust. Linux namespaces plus seccomp are the lightweight floor underneath both: namespaces give the process its own view of the filesystem and network, seccomp-bpf restricts which system calls it can even make so you can forbid raw network sockets at the kernel level, and a CPU limit and memory limit stop a runaway agent from exhausting the host. Pick gVisor for the laptop, a Firecracker microVM for untrusted code, and namespaces plus seccomp as the floor. None of them is a magic word; all of them are a real boundary.
The cloud vendors already agree, which is the strongest signal this isn’t fringe paranoia. Google’s GKE Agent Sandbox is generally available, gVisor-backed, and ships with a default-deny network policy already on, built specifically for running “untrusted, LLM-generated code” safely.
The approval gate: ask before it acts
The fourth wall is a pause, not a barrier. For the small set of genuinely destructive actions, the agent should stop and get a human yes. This is shipping in real tools, and the implementations are worth copying. Codex has a clean two-flag gate:
codex --sandbox read-only --ask-for-approval untrusted # the reading path
codex sandbox linux # run a command under bubblewrap-based host isolation
# (macos uses Seatbelt, windows uses a restricted token)Under --ask-for-approval untrusted, only commands Codex considers read-only run freely; everything else escalates to you. The --sandbox levels are read-only, workspace-write, and danger-full-access, and the right default for anything that reads your email is the most restrictive one the task tolerates, never danger-full-access. On Claude Code the equivalent dial is --permission-mode, kept well away from bypassPermissions. The principle under every flag: read-only work flows, destructive work pauses, and the enforcement lives in the tool, not in a polite request to the model.
Prove the box holds
Now attack your own box by hand before you trust it. Run these as the agent would, from inside the box, and confirm each one fails:
# Wall 1 (filesystem): writing outside the working dir must be denied
echo test > ~/.ssh/should_not_work # expect: Permission denied / Read-only file system
# Wall 2 (egress): anything off the allowlist must be refused
curl -m 5 https://example.com # expect: timeout / connection refused
curl -m 5 https://gmail.googleapis.com # expect: success (this one IS allowed)
# Wall 3 (approval gate): a destructive action must pause, not run
# trigger a delete and confirm you get a y/n prompt, not an outcomeIf the first two succeed when they should fail, your box has a hole, and a hole in a box is worse than no box because of the false confidence. The two-line curl test is the one to re-run every single time you change the agent’s environment, because egress is the wall that quietly springs leaks.
What should you actually do?
- On your laptop → this is the least-sandboxed place most people run agents and the one with the juiciest loot (your SSH keys, your cloud creds). Run the gVisor box plus the read-only filesystem. Treat your dev machine as production, because to an attacker it is.
- In CI → use ephemeral containers, no standing credentials, and default-deny egress so a compromised build can’t exfiltrate your source or signing keys.
- In production → reach for a Firecracker microVM per task or GKE Agent Sandbox, so one poisoned request can’t reach the next user’s data.
- Whatever you build → name the isolation tech instead of waving at it, then fire the
curlandecho > ~/.sshtests at it. A box you haven’t attacked is a box you’re guessing about.
The bottom line
- The egress allowlist is the highest-payoff wall in the whole box. One rule turns “any compromise leaks everything” into “a compromise leaks nothing,” because the loot has nowhere to go.
- A sandbox is architecture; a refusal is weather. The box doesn’t care what the attack is, which is exactly why it holds against attacks you never thought to test.
- Install the wall outside the agent’s reach. If the agent can flush its own iptables, you don’t have a wall, you have a suggestion.
Frequently Asked Questions
How do you sandbox an AI agent?+
Put it behind four walls: an isolation runtime (gVisor, a Firecracker microVM, or namespaces plus seccomp), a read-only filesystem with one writable directory, a default-deny network egress allowlist, and an approval gate for destructive actions. Then attack each wall to prove it holds.
What is the most important wall in an agent sandbox?+
The egress allowlist. Almost every attack that hurts you needs the network to exfiltrate or phone home. Deny outbound by default and allow only the few hosts the task needs, and you break most attacks even after every other layer fails.
Is gVisor or Firecracker better for sandboxing an agent?+
gVisor is the lower-friction default for an agent on your laptop (one Docker runtime flag). Firecracker microVMs give a stronger virtualization boundary for code you genuinely don't trust, which is why AWS runs Lambda on them.